
|
Articles in this issue :
|
A Rose By Any Other Name...
Our little rag is growing up! You may have noticed we've changed the name of our montly on-line publication
from "The JavaRanch Newsletter" to "The JavaRanch Journal".
Since its inception almost two years ago, the talented authors behind this publication have contributed many
informative articles creating a trove of knowledge read by many developers. We felt this collection of articles
had begun to outgrow the publication's original name, and a new name was warranted.
Over the next few days and coming weeks, you might notice some changes as we spiff up the place and clean out
those cobwebs of url patterns referencing "newsletter" to make some space for many more excellent articles to come.
We'd like any feedback on the JavaRanch Journal you might have. Love something? Hate something? Have an article to contribute? If you've anything to share, send me a note at dirk@javaranch.com. I hope to hear from you.
-- Dirk Schreckmann, The JavaRanch Journal Managing Editor
Discuss this article in The Big Moose Saloon!
Return to Top
|
Pattern: Distributed Cache Update
The Distributed Cache Pattern
Kyle Brown
Senior Technical
Staff Member
IBM Software Services
for WebSphere
Introduction
In early 2001, while working with Martin Fowler in reviewing
the patterns in what would become his book Patterns of Enterprise Application
Architecture, the two of us began searching for patterns describing
asynchronous messaging. At the time, we thought that this might become a
section within PoEAA, but we quickly realized that the subject was far too
broad to fit within the context of that book.? Martin and I then began hosting
a series of pattern-mining meetings, including Booby Woolf and Gregor Hohpe,
which eventually led to their book, Patterns of Enterprise Integration:
Designing, Building and Deploying Messaging Solutions.? That book describes
a rich and robust pattern language for working with asynchronous messaging, web
services, and enterprise application integration tools.?
However, as the group started work in earnest on that project,
we found that there were a few patterns that simply did not fit into the rest
of the pattern language.? By far the most well-known of these and the one for
which we had the most examples, was the Distributed Cache Pattern.? Even
thought it didn?t fit into the Patterns of Enterprise Integration catalog, it?s
still an interesting and useful pattern that should be part of the advanced
J2EE designer?s toolbox.?
What are patterns
For those of you who are completely unfamiliar with Patterns
literature, you may want to first take a look at either of two books referenced
above, or Design Patterns: Elements of Reusable Object-Oriented Software,
in order to see what to expect from patterns and pattern languages.?? In brief,
a pattern is a reusable software asset in its most abstract form ? a pattern is
a description of a solution for a common problem that has been applied in a
standard way a number of times.? The particular style of pattern that we will
use (which is the same one used in Patterns of Enterprise Integration) was
originally developed by Kent Beck in his book Smalltalk Best Practices
Patterns.? It expresses the problem that the pattern solves in highlighted
text, and then, after a discussion of what makes the problem challenging,
provides the solution in highlighted, italic text, followed by more details on
the solution.??
So now that you?ve seen how the pattern came about, and how
it will be presented, it?s time to move on to discussing the pattern.
Distributed Cache
Your application is distributed over several physical
machines for scalability.? It uses a database for object persistence, but many
of the queries to the database take a long time to execute due to the
complexity of the queries.? My database queries cannot be further optimized, so
it is impossible to gain more speed through database tuning approaches.? You
would like to cache my data on each machine; however, you cannot cache all of your
data locally since the data does change, and the values in each cache will
begin to differ from the database and each other over time.?
How can you connect a set of distributed caches such that
updates are propagated across the caches and the same values can be returned
from queries on any of the caches?
Many systems are designed with a set of data caches to
improve performance.? For instance, in a system built using Enterprise Java
Beans (EJBs) you may use Entity Bean Option A caching [EJB], or we keep value
objects in memory in a singleton [Brown].? However, each of these options have
the same drawback; for instance, in Option A Caching, once a CMP EJB is read
from the database, the values held in memory do not change, even though the
corresponding values in the underlying database may change.
Most distributed HttpSession schemes also are a type of
distributed data cache. The similarity of each of these approaches has led to
the recommendation of a specific API for caching, the JCache API, as JSR-107
[JCache].?? Unfortunately, the cache is not the ?system of record? for most of
this information. In almost all cases, the ultimate place where data is stored
is in a database, thus creating a situation where the information in the
database and the information in an in-memory cache can drift out of
synchronization.? When the database is updated by one machine, if a query is
run against the (older) data in the cache on another machine it will return the
wrong value.
Some systems have been built such that the database itself
is responsible for updating the set of distributed caches.? These systems use
database triggers to force the update of each cache.? The problem with this
approach is that it is not standards-based and thus is not portable.? Thus a
system built using Oracle database triggers will not work if the database is
changed to DB2 or SQL Server.? Also, not every database (for instance some of
the open-source databases like MySQL) supports advanced database features like
triggers.
Thus, we need a way to force an update of each cache
whenever an object is changed in any cache.? Therefore:
Propagate cache updates using Publish-Subscribe
messaging such that whenever a change is made to an object in one cache, that
server will to notify all other caches that the object has been changed.
If a cache receives a notification it can choose to refresh
its values from the database (shared) version at notification time, or it may
simply mark it as "dirty" and read it back from the database whenever
anyone asks for it. The structure of these solutions is shown below (Figure 1:
Distributed Cache Update).? ?Another option would be to update the cache from
the message. However, this is not as desirable as reading from the DB since it
would require object hydration from a message instead of from the database;
this both complicates the messaging code, and also increases the amount of
message traffic in the system as a whole since the entire object, rather than a
notification, must be sent in the queue.?
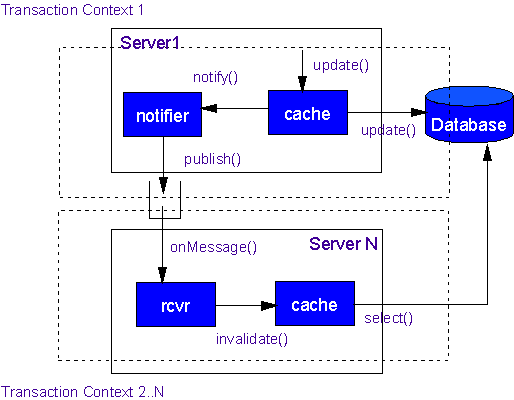
Figure 1: Distributed Cache Update
It is important to keep the granularity of the cache high
such that the total number of messages flying across the messaging system is
kept to a minimum.? In many cases, this can be achieved by sending out only
notifications about the "root" object of an object graph whenever any
part of the graph changes. Within a transaction you hold off notification until
all updates complete so that we can remove redundant messages.? Likewise, it is
desirable to have the ?put? onto the queue be part of the same transaction as
the update to the database (e.g., make the cache a Transactional Client)
so that the state of the database does not diverge from the known state of the
caches (Figure 1 shows the database update and the message being part of the
same transactional context, labeled ?Transaction Context 1?).
You can reduce the amount of unnecessary processing that
each cache must perform in handling update messages for objects it does not
contain by introducing multiple topics (one for each "root" type).?
The cache could use Message Selectors to filter out notifications about
objects they are not interested in, but that does not reduce the total number
of messages that are placed on the topic ? it only reduces the amount of
processing each client will perform.
It is also crucial that this solution only be used in cases
where it is not crucial that all caches remain perfectly synchronized at all
times.? This is because the solution necessitates the use of at least two
transactions; one on the ?notifying? cache side, and another for each of the
?notified? caches. This is shown in Figure 1 where the receiving end (Server N)
is shown to be executing in a separate transactional context from the original
transactional context. ?Thus, there can be a period of time while updating is
occurring in which queries to one of the outlying caches can return stale
data.? There is also the possibility of undeliverable messages, incorrect
update processing, and other situations that can render this solution less than
100% reliable. However, in most applications, so long as all final decisions
depend solely upon the state of the database of record the unreliability of
this solution can be tolerated.
This approach has been used successfully in commercial Java
application server implementations.? For instance, IBM WebSphere Application
Server 5.0 uses this approach in synchronizing its HttpSession, Dynamic page,
and Command caches through a common set of internal WebSphere frameworks. ?Likewise,
this is a feature of WebLogic Application Server 6.1.
SpiritSoft sells a product called SpiritCache [SpiritSoft]
that implements a JSR 107-compatible cache using this pattern that will work
with many application servers.? Likewise, Tangosol sells a product set named
Coherence that also implements this pattern.? Finally, a specific
implementation of this pattern restricted to EJB Entity Bean caching has been
previously documented in [Rakatine] as the Seppuku pattern.
Bibliography
[Brown] Kyle Brown, Choosing the Right EJB Type, IBM
WebSphere Developer?s Domain,
http://www7.software.ibm.com/vad.nsf/Data/Document2361?OpenDocument&p=1&BCT=66
[EJB], EJB 1.1 Specification, Sun Microsystems, http://java.sun.com/products/ejb/docs.html#specs
[Hohpe] Gregor Hohpe, ?Enterprise Integration Patterns?,
http://www.enterpriseintegrationpatterns.com
?[JCache], JSR 107; JCache ? Java Temporary Caching API, http://www.jcp.org/jsr/detail/107.prt
[Rakatine] Dimitri Rakatine, ?The Seppuku Pattern?, The
ServerSide.com Newsletter #26, http://www.theserverside.com/patterns/thread.jsp?thread_id=11280
[SpiritSoft] SpiritCache overview, http://www.spiritsoft.com/products/jms_jcache/overview.html
[Woolf] Bobby Woolf and Kyle Brown, ?Patterns of System
Integration with Enterprise Messaging?, submitted to the PLoP 2002 conference,
http://www.messagingpatterns.com
Discuss this article in The Big Moose Saloon!
Return to Top
|
The Web: Not Ready for Prime Time?
The Web:?Not Ready for Prime Time?
Jeff Johnson,
author of Web Bloopers.
The dot-com crash of 1999?2000 was a wake-up call.? It told
us the Web has far to go before achieving the level of acceptance predicted for
it in 1995.? A large part of what is missing is quality.? Put bluntly, the Web
has not attained commercial quality ? the level of quality consumers expect
from products and services.
A primary component of the missing quality is usability. The
Web is not nearly as easy to use as it needs to be for the average person to
rely on it for everyday information, communication, commerce, and
entertainment.
A Few Choice Bloopers
As an example of poor quality and low usability, look at a
Search results page from WebAdTech.com, an e-commerce site (Figure 1).
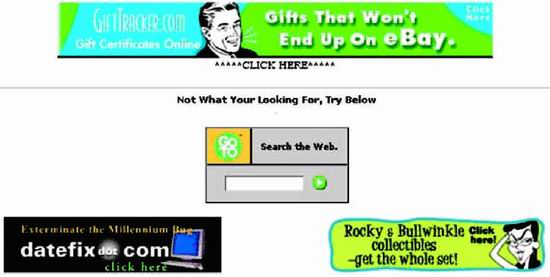
Figure
1. www.WebAdTech.com (Dec.
2000)?No page identification; poorly written error message hard to spot amid
ads; unhelpful website search box.
The results are for a search that found nothing. The page
has several serious problems:
?
Where
am I? Neither the site we are in nor the page we are on is
identified.
?
Where are my Search results? The page is so full of ads, it is hard to spot
the actual search results.
?
Huh? The
message shown for null search results is written in such abysmal English (not
to mention inappropriate capitalization), it is hard to understand.
?
What now? The
remedy offered for not finding anything is a box for searching the entire Web.
Not surprisingly, WebAdTech was one of the casualties of the
dot-com crash; it is gone.? However,
many sites with? significant usability problems remain.? For example, searching
for my name at the Yale Alumni website yields three Jeff Johnsons, with no
other identifying information (Figure 2). The only way to find the right one is
by clicking on them.
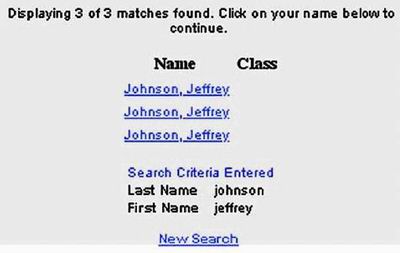
Figure
2. www.aya.yale.edu (June
2002)?Found items all the same.
There
is also the site map at a Canadian government site that seems to have been
designed based on the game of bingo (Figure 3). Not very useful, eh?

Figure
3. www.cio-dpi.gc.ca (Dec.
2000)?Cryptic site map.
Unfortunately,
poorly designed websites are all too easy to find.? Consider the following
examples:
?
The auto company site that pops up ?Method Not Allowed. An error
has occurred.? when visitors do things in the wrong order.
?
The state unemployment form that won?t accept former employer
names like ?AT&T? and ?Excite@Home? because of ?non-alphanumeric?
characters.
?
The intranet Web-based application that displays large buttons
but ignores clicks that aren?t on the buttons? small text label.
?
The computer equipment company site that contradicts itself about
whether its products work with Macintoshes.
?
The airline website that can?t remember from one page to the next
the time of day you want to fly.
?
The bus company site that, failing to recognize a customer?s
departure or arrival city, substitutes the one in its list that is nearest?alphabetically!
Unfortunately, the examples are endless. The Web is teeming with
bloopers.
Poor Usability Is Stifling the Web?s Growth
Others agree that the Web is sorely lacking in usability.?
One author provides a blow-by-blow account of the frustrating experience he had
trying to buy a wrench over the Web (Casaday 2001). Unfortunately, his
experience elicits sympathetic grimaces from anyone who has shopped on the Web.
More systematic surveys have found the same sad truth.? A
recent survey of 2000 Web shoppers found that approximately half of the people
surveyed were ?neutral to very disappointed? with the websites they used (Rubin
2002). A Forrester report issued in April 2002 argued that the Web represents a
large step backward
in usability from desktop software (Souza 2002).
Most tellingly, a survey by Consumer?s Union found that two thirds of
Americans distrust and avoid e-commerce websites.? This is higher than the
percentage of Americans who distrust the federal government or?even in the wake
of the Enron and WorldCom scandals?large corporations.? A reporter summarizing
the Consumer?s Union survey suggested that the problem is mainly that
e-commerce websites are not designed in a user-centered fashion:
These sites were often designed by
computer programmers. . . . The designers frequently attempted to draw
customers with technological bells and whistles while excluding the kind of
practical information?return policies, for example?that?s generally easy to
find in a bricks-and-mortar retail setting. (Paul 2002)
The bottom line is that for the general population, the Web
is low in quality, confusing, aggravating, and insufficiently useful.? Poor
usability is a big part of the problem.? To achieve its potential, the Web?s
usability must be improved.
Origins of the Web
To better understand why the Web has not yet attained
consumer-level quality, it is useful to review where it came from and how it
grew.
The World Wide Web was created in 1990 by Tim Berners-Lee to
allow particle physicists to share information with each other over the
Internet more easily. Before then, people shared information on the Internet
using various programs and protocols: email, FTP, Gopher, and others. The Web
standardized and unified data formats and file-transfer protocols, greatly
simplifying the sharing of computer files. It defined HTML as the primary
format for documents. Naturally, the first websites were created and hosted
where Mr. Berners-Lee worked: the Centre European Research Nuclear (CERN)
particle-accelerator facility in Geneva, Switzerland.
To access the Web, a Web browser is required. Tim
Berners-Lee wrote the first browser and released it to the physics research
community when he announced the World Wide Web.? This first browser worked only
on the NeXT computer.? Like today?s browsers, it displayed ?rich? text?bold,
italics, fonts?formatted in HTML, and it displayed links as clickable
underlined text. However, it displayed only text. Images, type-in fields, and
other controls, if required by a website, had to be displayed in separate
windows, using specialized browser plug-ins and protocols. Because many early
Web users did not have NeXT computers, other browsers were soon written. For
example, many physicists in the early 1990s used a text-only ?line-mode?
browser that ran on most Unix computers. This ?line-mode? browser was not at
all graphical: It displayed only plain text and showed links as bracketed
numbers next to the linked text (e.g., ?black hole [2]?). To follow a link, you
typed its number, as in many character-based library catalog systems.
The first U.S. website was put up in 1991 by Paul Kunz at
the Stanford Linear Accelerator in northern California (Figure 4). The main
information available on the Web in those early days was physics experiment
data, an index of physics papers, and address directories of physicists.

Figure 4. slacvm.slac.stanford.edu (Dec. 1991)?Home page of
first U.S. website, viewed through the NeXT Web browser, which displayed only
text.? This page links to two databases: a directory of Stanford Linear
Accelerator employees and an archive of high-energy physics papers. (To visit
this page and more of the first U.S. website, go to www.slac.stanford.edu.)
After 3 years of obscurity, the Web took off in 1994, when
the National Center for Supercomputing Applications (NCSA) at the University of
Illinois released Mosaic.? Developed mainly by students, Mosaic was a graphical
?point-and-click? Web browser, available for free. Unlike the NeXT browser,
Mosaic could display images. Immediately, people in technical professions began
creating websites, for both work and pleasure. They were soon followed by a few
pioneering online businesses. The Web began growing exponentially: 100 sites;
1000; 10,000; 100,000; 1,000,000; and so on. By the late 1990s, the number of
websites was growing so rapidly that most attempts to plot it went essentially
straight up.
Rise of the Web: Everybody Who Creates a Site is a Designer
The meteoric rise in popularity of the Web immensely
broadened access to information?and misinformation.? Most relevant to this
article, the rise of the Web has thrust many people into the role of
user-interface designers . . . for better or worse. Furthermore, this trend
will continue.? Although the dot-com crash of 2001 slowed the growth of the
Web, it did not stop it. Credible estimates of the total number of websites
vary tremendously?from about 15 million to 200 million?because of differences
in how a ?website? is defined.? Nonetheless, Web analysts agree that whatever
the number of websites is, it is still growing.
Every one of those websites was designed by someone.? As
Nielsen has pointed out (Nielsen, 1999a), there aren?t enough trained
user-interface designers on Earth to handle the number of websites that go
online each year. Thus most sites are designed by people who lack training and
experience in interaction and information design and usability.? Put more
bluntly: everyone and his dog
is a Web designer, and almost no one has any user-interface or
interaction design training.
In addition to the explosion in the number of Web designers,
we had the ascendancy of ?Internet time??extremely aggressive schedules?for Web
development.? Internet time meant no time for careful analysis of the intended
users and their tasks, no time for usability testing before taking the sites
live, and no time for sanity checks on the? soundness of the site?s value
proposition. From the late 1990s through about 2000, thousands of
companies?many of them startups?developed websites and Web-based applications
?on Internet time.? Business plans were devised on Internet time, large sites
were designed on Internet time, and back ends and front ends were implemented on
Internet time.? Not surprisingly, most of these efforts then crashed and burned
. . . on Internet time.? Lesson: Maybe ?Internet time? is not such a great
idea.
Avoiding Past Web Design Bloopers
To paraphrase a well-known saying, those who don?t understand
the Web-design bloopers of the past are condemned to repeat them? and repeat
them? and repeat them.? I wanted to help Web designers get past endlessly
repeating bloopers, especially those that are common and avoidable.
Towards that end, I spent several years collecting and
categorizing examples of Web design bloopers.? The most common ones were
recently published in a book:? Web Bloopers:? 60 Common Web Design Mistakes
and How to Avoid Them (Morgan Kaufmann, 2003). The book uses actual website
examples to illustrate common design mistakes that frustrate and confuse people
and ultimately drive them away.? Each blooper described in the book is followed
by an explanation of how to avoid it.
In collecting examples of bloopers, I avoided personal
websites and websites of very small businesses and organizations.? Individuals
and small organizations usually don?t have much money to spend on Web
development, so it isn?t surprising that their sites contain bloopers.? Also,
websites of individuals are often more for personal expression than anything
else and so must be viewed with great tolerance.
Inste?ad, I focused on larger organizations:? companies,
government agencies, and non-profit orga?nizations.? All have??or at least
should have?put significant effort and resources into designing and developing
their sites.
My hope is that by learning to recognize and avoid common
design bloopers, we will bring the Web closer to the commercial quality
necessary for acceptance by mainstream consumers.
For more information about Web Bloopers, please see
www.web-bloopers.com.
References
Casaday, G. ?Online Shopping, or How I Saved a Trip to the
Store and Received My Items in Just 47 Fun-filled Days?, Interactions,
Nov/Dec 2001, pages 15-19.
Nielsen, J. ?User Interface Directions for the Web?, Communications
of the ACM, 42, 1999, pages 65-71.
Paul, N. ?Labels Slowly Build Trust in the Web?, C.S.
Monitor, 13 May 2002, page 18.
Rubin, J. ?What Business Are You In??? The Strategic Role of
Usability Professionals in the ?New Economy? World?, Usability Interface,
Winter 2002, pages 4-12.
Souza, R., ?The X Internet Revives UI Design,? Forrester
Tech Strategy Report, April 2002, Cambridge, MA: Forrester Research, Inc.
Discuss this article in The Big Moose Saloon!
Return to Top
|
Working with the Internationalization and Formatting Actions
Practical JSTL - Part II
By Sue Spielman
In part I of this series, we took a look at the basic idea
behind the JSTL and the powerful standard actions that are provided within it.
We had an overview of the functionality of the Core tag library, as well as how
you can use the EL. In part II, we?ll take a look at some of the other
functionality provided for us. We?ll touch base on the available standard
actions contained within the JSTL in the XML, I18N, and SQL libraries.
The following sections are excerpted from various
sections and chapters within the ?JSTL:
Practical Guide for JSP Programmers?. You can find complete details
of all of the standard actions available in the JSTL, as well as a developer?s
quick reference guide, provided in the book.
Working with the XML Actions
The XML tag library brings us to actions that deal with XML
manipulations. I am hard pressed to think of any application that I?ve
developed in the last few years that didn?t use XML to represent the data in
the web tier. XML is the data format of choice for exchanging information.
Keeping this in mind, it?s relevant to discuss the number of actions that JSTL
provides to help a page author deal with XML. You will find a strong similarity
between the XML core actions and the actions provided in the Core tag library.
But there is a difference; that being that the XML core actions use XPath for
their expression language.
Using the Select Attribute
All of the XML actions of JSTL allow a way to specify XPath
expressions. This is accomplished by using the select
attribute. The select attribute
is always specified as a string literal that is evaluated by the XPath engine.
It was decided to have a dedicated attribute for XPath expressions so as to
avoid confusion. Since some of the XML actions have similar functions to the
Core actions, it was important not to get the XPath expression confused with
the JSTL expression language. The select
attribute is shown in this simple sample where the XPath expression
specifies the title to be selected from the XML document and output to the JspWriter.
<x:out
select=?$catalog/book/title?/>
Accessing Resources
When using XML actions, obviously one of the first things we
want to do is access some
type of resource like an existing XML document. This is done
by importing resources using the Core URL action <c:import>.
The resource can then be used by such XML actions as <x:parse> and <x:transform>. For
example, we can import a URL resource and then export it into a variable named xml. This variable is then
used as the XML document to the parse action as shown in the sample below.
<c:import
url="http://www.mkp.com/book?id=12345" var="xml"/>
<x:parse xml="${xml}"
var="doc"/>
Parsing XML Documents
The first step required before being able to access any of
the information contained in an
XML document is that it must be parsed. Usually there is an
existing document that you want to be working with. This document might be the
result of some business logic that was performed in the business tier of your
application. We want now to deal with it in the presentation tier so that we
can display the results appropriately. Using the <x:parse>
action is how we get the information from XML format into some format that can
be used by XPath, and XSLT. <x:parse>
takes a source XML document, parses it, and produces a scoped variable
that holds the results. The variable can be defined by either using the var or varDom attribute. There are
two different types of attributes because there are a number of ways to
represent XML documents. JSTL provides the flexibility for the implementer of
the specification to return an object of its choosing in the var attribute.
<x:parse> Action
The <x:parse>
action is used to parse an XML document. The resulting object is then
saved into a scoped variable as defined by either the var or the varDom
attribute. The varDom
attribute is a String that
holds the name of the scoped variable. The type of the scoped variable is an org.w3c.dom.Document. The
type of the var attribute
depends on the implementation of the <x:parse>
action, so you will need to consult the documentation for it. In the
reference implementation of the JSTL, the type of the scoped variable as
defined by var is also
of type org.w3c.dom.Document.
The <x:parse> action
performs the parse on the document; it does not perform any validation against
Document Type Definition files (DTDs) or Schemas. The XML document to be used
for the parse can either be specified with the xml
attribute, or it can be specified inline by including it the action?s
body content.
The varDom
attribute exposes a DOM document, making it possible to use the variable
for collaboration with other custom actions you might have created. Objects
exposed by
var and
varDom can be used to
set the context of an XPath expression. This is exactly what we?ll see in our <x:set> and <x:out> example when
we reference the $doc in
the select attribute. In the sample below, we import a document using the <c:import> action.
Then we use that XML document for the parse. The results are stored in the var attribute of the parse
action. We then use doc as
the context for our other XML actions.
<c:import
url="http://www.mkp.com/catalog.xml" var="xml"/>
<x:parse source="${xml}"
var="doc"/>
<x:out
select="$doc/catalog/book/title"/>
If your source XML document is null or empty,
a JspException will be
thrown.
A common way to identify the XML file is to use the parse to
expose it as an imported resource. By using the <c:import>
action, we access the XML file and then use the EL to pass it to the <x:parse>. This is
shown in Example 1.
Example 1 <x:parse> Using an Imported XML
Document
<c:import var="xmlfile"
url="/people.xml" />
<x:parse var="doc"
xml="${xmlfile}" />
Hello <x:out
select="$doc/person/firstname" />
Using XML Documents to Determine Flow Control
While the XML core actions provide the basic functionality
to parse and access XML data, the XML flow control actions are used to do
conditional processing and iterations. The same way that we used various Core
actions for flow control in our JSPs can be applied to the conditional actions
available in the XML tag library. In fact, the XML actions mimic the Core
actions. The actions available are:
<x:if>
<x:choose>
<x:when>
<x:otherwise>
<x:forEach>
The only difference between the two libraries, which you
might have guessed by now, is the fact that the select
attribute uses XPath instead of the EL when working with the <x> actions. Using
XPath expressions, the XML control flow actions determine whether to process
JSP code. These actions act in much the same way as the Core tag library flow
control actions we already talked about, except for the utilization of XPath
instead of the expression language. Therefore, to avoid redundant information,
I am going to point out the differences between the XML and the Core actions (<c:if>, <c:choose>, and <c:forEach>), where
appropriate.
The biggest difference is that the select attribute is evaluated to a boolean expression according
to the semantics of the XPath boolean()
function. Otherwise, everything that you?ve already learned applies to
the control flow actions can be applied here as well. You?ll notice that before
you do any type of control flow, you always have to have a document available.
This means that you always have to do an <x:parse>
on the document so that it can be accessed through a variable.
The XML actions play an important role in today?s web
applications. Since XML is omnipresent, dealing with XML documents becomes much
easier with the actions provided in the XML tag library. Using the XML actions,
it?s possible to do all sorts of data comparison, iteration, and
transformations using XSLT. All of these actions should make your page
authoring that much easier. In order to make the best use of the XML actions,
it is important to have a firm understanding of XPath and XSL at the very
least.
Working with the Internationalization and Formatting Actions
More than likely, the application you are developing today
will have to be internationalized tomorrow. Wouldn?t it be great if the effort
required to internationalize your application could be reduced to zero? Well
okay, that might be too optimistic to hope for since anyone who has developed
applications for international use knows there is always something that needs
to be tweaked. Luckily, the internationalization and formatting actions
provided in the JSTL are a comprehensive set of actions that can be used to
minimize the headaches of having to internationalize your application. These
actions come under the functionality of the I18N umbrella. I18N, which refers
to the 18 letters between the I and
the N in internationalization, is a common
acronym used when talking about internationalization features. It is also
common to use the term L10N, for localization. In this chapter, we?ll explore
these internationalization actions. All of the actions related to I18N are
contained in the custom tag library with the URI http://java.sun.com/jstl/fmt
and are frequently accessed by using the fmt
prefix x.
The I18N functional area can be broken down into two main
areas:
1.Locale and resource bundles that include such actions
as:
?
<fmt:setlocale>
?
<fmt:bundle>
?
<fmt:setBundle>
?
<fmt:message>
?
<fmt:param>
?
<fmt:requestEncoding>
2.Formatting for numbers, dates, and currency, which
includes such actions as:
?
<fmt:timeZone>
?
<fmt:setTimezone>
?
<fmt:formatNumber>
?
<fmt:parseNumber>
?
<fmt:formatDate>
?
<fmt:parseDate>
To address both of these functional areas, let?s first
take a cursory look at what pieces are involved in creating international
applications. Then we?ll look at how these pieces can be put to work using the
various actions available in the JSTL.
First,the <fmt:message>Action
Before we start talking about the various actions
available in the I18N, let?s introduce the <fmt:message>action.
If you really wanted to do the bare-bones amount of work necessary to build an
internationalized application,<fmt:message>is
the only action that you?ll need to consider. The <fmt:message>action takes advantage of
the LocalizationContext. By
using the <fmt:message>,you
can output values from your resource bundles as simply as:
<fmt:message key=?welcome?/>
The appropriate resource bundle will be used to look up
the key ?welcome? and the translated string will be provided. This is about as
easy as it gets to incorporate international support into your application. The
<fmt:message>action
also supports parameterized content, also called parametric replacement. For
example, you can provide variables that will be used within the string used by
the key attribute. Say
we want to personalize our welcome page and pass the name of a user so that we
can welcome them. To do this, we use the <fmt:param>
subtag. A quick example, so that you are familiar with the format, the
action might look like:
<fmt:message key=?welcome?>
<fmt:param value=?${userNameString}?/>
</fmt:message>
In this example, we would be accessing a variable already
set, called userNameString ,
that would then be used as a parameter to the message. If we were accessing the
English version of the resource bundle,Welcome Sue would appear in the JspWriter .
Author Note: Chapter 6 of the JSTL: Practical Guide -? Working
with the Internationalization and Formatting Actions - continues by going into
great detail on how to work with Locales, resource bundles, and all of the I18N
standard actions.
Using the SQL Actions
The JSTL includes a number of actions that provide a
mechanism for interacting with databases. The previous sentence should, at a
very minimum, send up a red flag in your architectural visions. One might ask, ?Do
I really want to be able to perform SQL actions such as queries, updates, and
transactions from my JSP? Isn?t that business logic that belongs in the model?
The answer is yes. Yes, yes, yes. To follow a Model-View-
Controller (MVC) architecture, which is the predominant
design pattern used in building web applications today, you definitely want to
keep your model information in your business logic. This means that you don ?t want it in your JSPs. Why
then are these actions even provided in the JSTL? Good question and one that
I?ve discussed with various members of the JSR-53 expert group. The reason is
the ?C? or community in the Java Community Process (JCP). The community has
asked for it, the community has gotten it.
Many feel that for prototyping, small-scale,and/or very
simple applications, or if you just don?t have the engineering staff to
implement a full MVC model, then the SQL actions might prove useful. While I
can (barely) see the point being made for use of the SQL actions for
prototyping or small-scale applications, I can?t ever validate the argument that
you just don?t have the time to implement an MVC model correctly. If that is
the one and only reason why you are choosing to use the SQL actions, then I
suggest that you investigate using such frameworks as Struts which is part of
the Jakarta projects and can be found at http://jakarta.apache.org/struts/index.html
. Struts is an MVC framework that can be learned quickly and will
provide a much cleaner architecture than having Model information located
throughout your JSPs. For a complete discussion on Struts 1.1 along with a full
sample application, refer to The
Struts Framework: Practical Guide for Java Programmers.
If you are careful about how you code your SQL actions, it
should be easy enough to pull out the code and put it into classes that
represent the Model interaction at a later point. I am not going to go into the
various design patterns that can be applied for doing business or integration
tier access. But if you consider using the SQL actions in your application, it
would be wise at least to familiarize yourself with such common patterns as
Transfer Objects, JDBC for Reading, Data
Transfer Object (DTO) Factory, Data Transfer Hashmap,and Data Transfer Rowset.
Doing so may help you avoid embedding the business logic/data access into your
JSPs so deeply that you are left with a tangled mess.
With that said, I don?t consider it an architectural flaw
to have the SQL actions included in the JSTL. However, I do consider it an
architectural flaw to use them in your application development. It is up to the
page author and application architect to make sure that the design patterns are
being adhered to correctly, if not for the maintenance issue of the application
then for the practice of good engineering. However, since these actions are
included in the JSTL, I must make sure you understand them and their features
so that you can make an informed decision.
The JSTL SQL actions provide functionality that allows
for:
?
Making database queries
?
Accessing query results
?
Performing database modifications
?
Database transactions
What all of the SQL actions have in common is that they
work against a specific data source.
The Available <SQL>Actions
There are six actions provided in this tag library:
?
<sql:setDataSource>for
exporting a variable that defines a data source
?
<sql:query>for
querying to the database
?
<sql:update>for
updating the database
?
<sql:transaction>for
establishing a transaction context for doing queries and updates
?
<sql:param>for
setting parameter markers (???) used in SQL statements.
<sql:setDataSource>
The <sql:setDataSource>
is used to export a data source either as a scoped variable
or as the javax.servlet.jsp.jstl.sql.dataSource
data source configuration variable.
Using the var
and scope attributes,
the data source specified (either as a DataSource
object or as a String)
is exported. If no var is
specified, the data source is exported in
the javax.servlet.jsp.jstl.sql.dataSource
configuration variable.
The data source may be specified by using the dataSource attribute. This
can be specified as a DataSource
object, as a Java Naming and Directory Interface (JNDI) relative path,
or using a JDBC parameters string. If you don?t want to use the dataSource attribute, it is
also possible to specify the data source by using the four JDBC parameter
attributes. All four of the parameters are just String
types. These attributes are driver,
url, user, and password. Using the JDBC
attributes is just an easier way to configure the data source than specifying
the values in the string syntax for the dataSource
attribute. In Example 2 we see how to specify a data source using the
JDBC parameters. We are making this data source available as an exported
variable called datasource.
This can then be used by other actions if they want to use this particular data
source, as shown by the <sql:query> action.
Example 2? Setting a Data Source
<sql:setDataSource
var="datasource"
driver="org.gjt.mm.mysql.driver"
url="jdbc:mysql://localhost/db"
user="guest"
password="guest"/>
<sql:query
datasource="${datasource}" ? />
<sql:query> Action
No mystery here, the <sql:query>
action is used to query a database. There are a number of attributes
that are used with this action. It is possible to specify a data source by
using the dataSource attribute.
If present, it will override the default data source. If the dataSource is null, then a JspException is thrown. If a
dataSource is
specified, then the <sql:query>
action must be specified inside of a <sql:transaction>
action. We won?t go into details about the <sql:transaction> in this article, but you can find out the
details in chapter 7 of the JSTL: Practical Guide.
A single result set is returned from a query. If the query
produces no results, an empty Result
object (of size zero) is returned. This would be the case for a SQL
statement that contained an INSERT,
DELETE, UPDATE, or any SQL statement
that returns nothing such as a SQL DDL statement. Returning an object of size
zero is consistent with the way return values are handled by the executeUpdate() method of
the JDBC Statement class.
This result set contains rows of data if there are results. The data is then
stored in a scoped variable that is defined by the var and scope
attributes. The default scope is page.
Obviously, there must be a way to specify the SQL query to
be used. This can be done by using the sql
attribute, or by including the SQL statement in the action?s body
content.
The code in Example 3 and that in Example 4 do exactly the
same thing.
Example 3 SQL Defined in Attribute
<sql:query sql="SELECT * FROM
books WHERE title = ?JSTL? ORDER BY author"
?
var="titles" dataSource="${datasource}" >
</sql:query>
Example 4 SQL In Body Content
<sql:query var="titles"
dataSource="${datasource}" >
SELECT * FROM books
WHERE title = ?JSTL? ORDER BY author
</sql:query>
Summary
At this point, you should have a full appreciation for the
power that the JSTL can provide. By reading both of the excerpt articles,
hopefully you have seen that this is just the tip of the iceberg. There are so
many projects out there that have JSP code that can utilize the JSTL; a great
place to start is just refactoring some of the pages you might already have.
You?ll see how easy and efficient it is using the JSTL compared to debugging
through scriptlet code that might be scattered throughout the pages. I hope
that the JSTL:
Practical Guide for JSP Programmers helps you get a head start on
everything you need to know about the JSTL to get rolling.
Sue Spielman is president and senior consulting engineer, of
Switchback Software LLC, http://www.switchbacksoftware.com
. Switchback Software specializes in architecture/design and development of
enterprise, web, and wireless applications. Sue is the author of ?The Struts
Framework: Practical Guide for Java Programmers?, ?JSTL: Practical Guide for
JSP Programmers? and ?The Web Conferencing Book?. She can be found speaking at
various technical conferences around the country. You can reach her at sspielman at
switchbacksoftware.com
Discuss this article in The Big Moose Saloon!
Return to Top
|
SSH Tunneling for Java RMI, Part-II
Pankaj Kumar, Author of
J2EE Security for Servlets, EJBs and Web Services, Nov. 2003
Copyright © 2003 Pankaj Kumar. All Rights Reserved.
Abstract
This article is the second and the last one in a series of two, describing use of SSH tunnel
for securing RMI based Java applications. The first part discussed the steps to setup SSH tunnel
for lookup of remote references
registered in a RMI registry and method invocations on "unicast" servers -- a special class of
remote objects that require the host JVM to be up and running at the time of the invocation.
In this part, we will go over a number of other issues that need attention in a
tunneled environment: callback methods, automatic download of code by the RMI system, activatable servers,
and corporate firewalls.
As we will see, SSH tunneling provides a much more
elegant solution to the problem of securely traversing the corporate firewalls than traditional
ones based on forwarding RMI calls over HTTP to a CGI program or a Servlet.
Brief Recap and Few Clarifications
As covered in the first part, a RMI client invokes methods on a remote object through remote
stubs. The remote stub contains information, such as the hostname or the IP address of
the host machine and the port at which the RMI system listens for incoming
connections, that allows it to communicate with the corresponding remote object. By default,
the RMI system randomly allocates a free port to the remote object
at the time of instantiation. Howerver, it is possible to specify a
fixed port number programmatically by using a specific constructor.
I also noted (errorneously, as it turns out) that it was not possible to specify the IP
address of the machine in a similar manner.
SSH tunneling works by requiring the remote stub to
communicate with SSH client program ssh on the local machine. This is achieved easily and
transparently if the hostname field of the remote stub
is set to "localhost" or "127.0.0.1", and not the hostname or IP address of the
machine hosting the remote object. I managed to accomplish this in the first part of the series
by actually modifying the DNS entry for the host machine so that resolving the hostname on the
server machine always returned "127.0.0.1". This is not elegant at all.
Fortunately, there exists a simpler mechanism to accomplish the same objective -- by setting
the system property java.rmi.server.hostname to "localhost" or "127.0.0.1"
for the JVM that instantiates the remote object.
To illustrate this, let us go over the main steps to run the example covered in the
previous article.
But before that, let recall our setup from the previous article -- a RedHat Linux box
(hostname: vishnu) acts as
the server machine and a W2K box acts as the client machine. Actually, any of these can run
the server or client program of our example. The distinction of the server and client
is only for the SSH. Only the Linux box runs the SSH daemon program sshd.
The source code available with this part includes examples covered in the first part as well
as those that we will use in this part. To better organize the source files for all the examples,
I have made some changes in the name of files and organization of source code. Please refere to
the Appendix A for details about the source files and their purpose.
To run our simple RMI example over SSH tunnel, the first step is to run the RMI Registry and
the server program server.Main2 on the Linux box (the server machine), in separate
command shells:
[pankaj@vishnu rmi-ssh]$ export CLASSPATH=.
[pankaj@vishnu rmi-ssh]$ $JAVA_HOME/bin/rmiregistry
[pankaj@vishnu rmi-ssh]$ java -Djava.rmi.server.hostname=localhost -cp . server.Main2
impl = server.EchoServerImpl2[RemoteStub [ref: [endpoint:[localhost:9000](local),objID:[0]]]]
EchoServer bound at port 9000 in rmiregistry.
Run the ssh program on the W2K box (the client machine) to setup the tunnel for both
RMI registry lookup and method invocations:
C:\rmi-ssh>ssh -N -v -L1099:vishnu:1099 -L9000:vishnu:9000 -l pankaj vishnu
This command runs the ssh program in verbose mode, ready to display a lot of
information on the use of the established tunnel. Keep in mind that this mode is
helpful only during initial setup and troubleshooting and is not appropriate for production
environment.
Now run, the client program in a separate command window:
C:\rmi-ssh>%JAVA_HOME%\bin\java -cp . client.Main localhost
RMI Service url: rmi://localhost/EchoServer
RMI Service stub: server.EchoServerImpl2_Stub[RemoteStub [ref: [endpoint:[localhost:9000]
(remote),objID:[1fc4bec:f8b94524cd:-8000, 0]]]]
Calling: stub.echo(Hello, Java)...
... returned value: [0] EchoServer>> Hello, Java
The screen output indicates successful invocation of the RMI method.
If you look at the window running the ssh program, you will see that all the
communication has taken place through the tunnel.
Handling Callback Methods
RMI allows remote objects to be passed to a server program by the client program and lets the
server invoke methods on this object. For the SSH tunnel, this essentially means allowing
connections to the client machine originating from the server machine through
the tunnel. One way to accomplish this is to have the SSH daemon sshd running on the
client machine
and establish a reverse tunnel from the server machine by launching ssh program there.
Another, less onerous way, is to setup the tunnel with reverse port forwarding. This is
accomplished by passing -R<local_port>:localhost:<remote_port> as
argument to the ssh program. With this setup, all the connections to the
<remote_port> on the server machine are forwarded to the
<local_port> on the client machine.
Let us see this setup in action by running the server program on the W2K box and
the client program on the Linux box. As earlier, the SSH tunnel is established by
running the ssh program on the W2K machine.
Run the rmiregistry in a command window of its own:
C:\rmi-ssh>set classpath=.
C:\rmi-ssh>%java_home%\bin\rmiregistry
Run the server program in another command window:
C:\rmi-ssh>%java_home%\bin\java -Djava.rmi.server.hostname=localhost -cp . server.Main2
impl = server.EchoServerImpl2[RemoteStub [ref: [endpoint:[localhost:9000](local),objID:[0]]]]
EchoServer bound at port 9000 in rmiregistry.
And the ssh program in the third command window:
C:\rmi-ssh>ssh -N -v -R1099:localhost:1099 -R9000:localhost:9000 -l pankaj vishnu
This tunnel is setup to forward all connections to port 1099 and 9000 on Linux box vishnu to the
W2K machine, where this program is running, making it possible to successfully execute the client
program on the Linux box:
[pankaj@vishnu rmi-ssh]$ $JAVA_HOME$/bin/java -cp . client.Main localhost
RMI Service url: rmi://localhost/EchoServer
RMI Service stub: server.EchoServerImpl2_Stub[RemoteStub [ref: [endpoint:[localhost:9000]
(remote),objID:[1bab50a:f8bc8813e9:-8000, 0]]]]
Calling: stub.echo(Hello, Java)...
... returned value: [0] EchoServer>> Hello, Java
Although we have demonstrated straight and reverse port forwarding separately, they can be
combined as shown below for two-way tunnel:
C:\rmi-ssh>ssh -N -v -L1099:vishnu:1099 -R9000:localhost:9000 \
-L9000:vishnu:9000 -l pankaj vishnu
(Note: character '\' denotes line continuation. An actual command must appear within a
single command line.)
In fact, it is also possible to include additional ports, for either straight or reverse
forwarding, in the same tunnel!
Automatic Code Downloads
So far, we have managed without setting up our server and client program to do any automatic
code download by keeping the stub classes in the CLASSPATH of the client. However, this is
not always feasible, or desirable. In such scenarios, RMI allows automatic code download.
The server program sets the location of the downloadable code,
which can be a file, http or ftp URL, by setting the system property
java.rmi.server.codebase and the client RMI system downloads the code.
Use of a http URL is quite common for the server program to make its code available to the
clients. Of course, this allows anyone to download the code, something which may not be desirable
in high security applications.
SSH tunneling can handle this easily by extending the tunnel for all the code download traffic
and restricting the download to only those machines that have been included in the trusted
network. One way to do this is to place the downloadable code in an appropriate sub-directory
of the HTTP server running on the server machine but allow only programs running on this
machine to access the HTTP server (this can easily be accomplished by use of iptables, as
illustrated in the first part of this series).
Let us run our example with code download. For this we will also have to enable Java
security manager at the client and specify a security policy file. As explaining code
security policy is not the primary objective of this article, we will use a very permissive
policy file as shown below:
// File: allperms.policy
grant {
permission java.security.AllPermission;
};
The first step is to run the program rmiregistry on the Linux box so that it down'd
find the stub class in its CLASSPATH or in current directory:
[pankaj@vishnu pankaj]$ export CLASSPATH=
[pankaj@vishnu pankaj]$ $JAVA_HOME/bin/rmiregistry
The next step is to run the main server program:
[pankaj@vishnu rmi-ssh]$ $JAVA_HOME/bin/java -Djava.rmi.server.hostname=localhost \
-Djava.rmi.server.codebase=http://localhost:8080/classses/ -cp . server.Main2
impl = server.EchoServerImpl2[RemoteStub [ref: [endpoint:[localhost:9000](local),objID:[0]]]]
EchoServer bound at port 9000 in rmiregistry.
Pay attention to the URL specified as the value of system property
java.rmi.server.codebase. It assumes that the stub classes can be found in the
classes sub-directory of the root directory of the HTTP server and the HTTP
server is listening for HTTP requests on port 8080. Also note that the URL has
localhost and not the hostname of the server machine. This is important for SSH
tunneling of code download requests.
The command to setup the SSH tunnel is almost the same, the only different being the fact
that now port 8080 is also being forwarded.
C:\rmi-ssh>ssh -N -v -L1099:vishnu:1099 -L9000:vishnu:9000 \
-L8080:vishnu:8080 -l pankaj vishnu
Finally, run the client program with appropriate system properties for security manager and
security policy file.
C:\rmi-ssh>%JAVA_HOME%\bin\java -cp . -Djava.security.manager \
-Djava.security.policy=allperms.policy client.Main
Activatable Servers
So far, we have dealt only with "unicast" servers -- a class of remote objects that require
the host JVM to be up and running for the client to invoke methods on them. In a general case,
the remote object could be activated by the RMI system, i.e., the rmid daemon program,
on demand. This case is also handled by the SSH tunneling, though the mechanism
to specify the hostname for the remote stub is somewhat different. The hostname now
must be specified as an argument to the rmid program so that it can pass this value to the
remote object at the time of activation.
This case demands different source code for the remote object implementation class and
the program that
registers the remote object with the RMI system. These sources can be found in files
server\EchoServerImpl3.java and server\Main3.java. We will not
describe the source files in details here as thry are not directly relevant for SSH tunneling.
The rmid daemon includes a RMI registry. This registry is accessible to other programs
in the same manner as the registry of the rmiregistry program, with the only difference
that by default, rmid listens at port 1098, and not 1099.
This fact must be accounted for while setting up the SSH tunnel.
The other difference is that both the rmid and the program that registers a remote object
must run with the Java security manager enabled and an appropriate security policy file must be
specified. For
simplicity, we will use policy file allperms.policy that we used in
the previous section.
Let us now run this the example. First, we launch the rmid daemon on the Linux box:
[pankaj@vishnu rmi-ssh]$ $JAVA_HOME/bin/rmid -J-Djava.security.manager \
-J-Djava.security.policy=allperms.policy \
-C-Djava.rmi.server.hostname=localhost
Here, the -C option directs the rmid to pass the option value to the
JVM that it launches to run the remote object after activation.
Next, run the program that registers the remote object with the RMI system.
[pankaj@vishnu rmi-ssh]$ $JAVA_HOME/bin/java \
-Djava.rmi.server.codebase="file:///home/pankaj/rmi-ssh/" \
-Djava.security.manager -Djava.security.policy=allperms.policy -cp . server.Main3
Activatable.register() = server.EchoServerImpl3_Stub[RemoteStub [ref: null]]
EchoServer bound to rmid at url: rmi://localhost:1098/EchoServer
Note that this program, unlike the previous server.Main2, exits after
registration with the RMI system.
Now, setup the SSH tunnel at the W2K box. Notice that we are using port 1098, and not 1099.
C:\rmi-ssh>ssh -N -v -L1098:vishnu:1098 -L9000:vishnu:9000 -l pankaj vishnu
Notice that we are using port 1098, and not 1099, as explained earlier.
Finally, run the client program.
C:\rmi-ssh>java -cp . client.Main "localhost:1098"
RMI Service url: rmi://localhost:1098/EchoServer
RMI Service stub: server.EchoServerImpl3_Stub[RemoteStub [ref: null]]
Calling: stub.echo(Hello, Java)...
... returned value: [0] EchoServer>> Hello, Java
Note that here also, we have specified 1098 as the port for RMI registry lookup.
Traversing Firewalls
There are occassions when we want some portions of a distributed program to be inside
a corporate firewall. Such firewalls typically disallow incoming connections but allow
outgoing connections through a web proxy or (now less often) SOCKS proxy.
RMI Specification includes
a mechanism to tunnel RMI messages over HTTP as a limited mechanism to allow clients behind
firewalls to invoke methods on remote objects outside the firewall. However, this approach has
many disadvantages: (i) it doesn't work when the server is behind a firewall; (ii) it doesn't handle
client side callbacks; (iii) it is not secure.
SSH tunneling provides a much more elegant solution to this problem through its proxy
command. You can configure ssh
to use HTTP or SOCKS proxy by placing host specific entries in the configuration file
~/.ssh/config, as explained at
the homepage of connect.c,
a freely available program to be used in the SSH proxy command.
A typical entry in the .ssh\config file for using HTTP proxy host <proxy-host> at
port <proxy-port> for all connections to the <outside-host> is shown below (You must change
it to use your setup specific values. Also, you need to have the executable connect.exe
in your PATH):
Host <outside-host>
ProxyCommand connect -H <web-proxy>:<proxy-host> %h %p
Once this setup is done, all the examples illustrated in earlier sections would work even if the
client machine is inside a corporate firewall. In fact, as we noted earlier, the distinction
between client and server machine is artificial. The only requirement is that the machine
running the sshd should be outside the firewall, ready to accept connections.
Even when all the machines are behind their own firewalls, one could setup a machine connected
to the internet, run the sshd on this machine and setup SSH tunnels through this machine
to allow seamless execution of distributed programs. The exact confiuration details for such
a setup is bit involved and outside the scope of this article.
Conclusions
This series of articles illustrated use of SSH tunnels as an effective mechanism for securing
RMI based distributed Java applications. Given the complementary nature of these two technologies --
RMI being excellent for building distributed applications but lacking security features and SSH
providing security features such as mutual authentication of communicating hosts, confidentiality
and integrity of messages, secure firewall traversal and so on -- it is bit surprising that this
combination has found very little discussion in the Java related technical literature.
Example source files are available in a single downloadable zip file:
rmi-ssh-src.zip. Download this file in your working directory and
and unzip it. This should create the sub-directory rmi-ssh and place the extracted
files and directories there. Run all your commands, including those for compilation and RMI
stub generation, from rmi-ssh directory.
To compile the sources and generate RMI stubs, run the commands:
c:\rmi-ssh>%JAVA_HOME%\bin\javac -classpath . server\*.java client\*.java
c:\rmi-ssh>%JAVA_HOME%\bin\rmic -classpath . server.EchoServerImpl1
c:\rmi-ssh>%JAVA_HOME%\bin\rmic -classpath . server.EchoServerImpl2
c:\rmi-ssh>%JAVA_HOME%\bin\rmic -classpath . server.EchoServerImpl3
A brief description of main source files is given below:
| File Name | Description |
|---|
client\Main.java |
The client program. Looks up the remote object and invokes the remote
method echo().
|
server\EchoServerIntf.java | Java interface for the server program. |
server\EchoServerImpl1.java |
An implementation of the remote object that allows any random port to be assigned. |
server\Main1.java |
Main program that instantiates server.EchoServerImpl1. |
server\EchoServerImpl2.java |
An implementation of the remote object that allows a fixed port to be assigned. |
server\Main2.java |
Main program that instantiates server.EchoServerImpl2 with port 9000. |
server\EchoServerImpl3.java |
An implementation of the remote object as an activatable server. |
server\Main3.java |
Main program that instantiates server.EchoServerImpl3. |
References
- J2EE Security for Servlets, EJBs and Web Services
- Remote Computing via Ssh Port Tunneling
- SSH Proxy Command with
connect.c
- RMI and Firewall Issues
Discuss this article in The Big Moose Saloon!
Return to Top
|
Retrospective of the <<UML>> 2003 Conference
by Valentin Crettaz
The Unified Modeling Language was created in 1996 by fusing the modeling languages
of three top OO development methods: the Booch method, OMT -the Object Modeling Technique method, by Jim
Rumbaugh et al- and OOSE -the Object-Oriented Software Engineering method, by Ivar
Jacobson-. UML has become the de facto standard for specifying,
constructing, visualizing, and documenting the artifacts of a
software-intensive system. It is used in an increasing number of different
domains, some of which are completely unrelated to software engineering. UML is
actively promoted by an impressive consortium of worldwide industries and
academia and is supported by more than one hundred professional software tools
whose primary goal is to facilitate the use of the language.
Since 1998, the Unified Modeling Language (UML) conference has gained in popularity
and has become an important worldwide event. Every year, several hundreds of
top researchers, practitioners and industry leaders from all over the world
attend the conference in order to present the results of their research to the
community, exchange opinions and advance the standard.
Last October (20-24), the International
Conference on the Unified Modeling Language (UML) was successfully held in San Francisco
where about 300 participants from all over the world met for the sixth time.
This year, about 30 high-quality technical papers were presented which greatly
contributed to the use and advance of UML, while focusing on understanding how to:
- manage models in a practical way,
- ensure timing and quality of services with UML,
- compose models and build architectures,
- transform models,
- use UML to develop web-based applications,
- test and validate models,
- improve UML/OCL,
- check the consistency of models and
- develop methodologies for building models.
Nine attractive workshops were organized in which participants could interact,
exchange opinions and share ideas in order to advance the state of the art in
various areas of research around the use of the UML. During the workshops, the
participants focused on how to:
Well-known experts, such as Bran Selic from IBM Rational, and others
presented exciting half-day tutorials on advanced topics and techniques related
to UML:
The conference also featured fascinating invited talks by Jean B?zivin
from the University of Nantes (France), Nicolas Rouquette
from NASA?s Jet Propulsion Lab (USA) and Martin Fowler
from ThoughtWorks (USA). Jean B?zivin entertained us for about 90
minutes on the "Model Driven Architecture (MDA): From Hype to Hope and
Reality". In his talk, Prof. B?zivin argued that
future versions of UML should offer support for aspects. Furthermore, he
advocated for a much simpler form of the UML specification because developers
were not paid for reading, writing or interpreting the specification but for
actually developing systems. Nicolas Rouquette made
an excellent reality check and tried to show how UML and MDA would help solve
numerous problems of integrating heterogeneous architectural styles to build
software-intensive systems. Finally, Martin Fowler gave an excellent talk in
which he provocatively and intentionally debated on what the whole point of UML
was about, what UML really is from his point of view, what it is not, what it
should be used for and where the UML community should go to provide better
support for developers.
The conference had two very entertaining panel discussions. The first one moderated
by Marko Boger (from Gentleware)
aimed at debating over the new major 2.0 revision of UML that will be released
in the first quarter of 2004. The panelists were people directly involved in
the revision of the upcoming UML version, UML 2.0. The common consensus in the
audience seemed to be that the UML 2.0 contained too many changes, and that
practitioners will undoubtedly have a hard time using it. The downside is that
the UML specification has doubled in size from about 700 hundred pages to more
than 1200 pages that are now split into four documents: the UML 2.0
Infrastructure, the UML 2.0 Superstructure, the UML 2.0 Object Constraint
Language (OCL) and the UML 2.0 Diagram Interchange. Cris Kobryn
admitted that although UML 2.0 was a big advance, they had gone two steps
forward and one backward. Cris further argued that in the future the step
backward would slightly disappear, but for now UML 2.0 should be regarded as
UML?? until all inconsistencies and issues have been resolved.
In the second panel discussion led by Bran Selic, the participants
were invited to share their ideas of what a good modeling language should look
like. The panel was composed of Steve Mellor, Jean B?zivin,
Bernhard Rumpe, Cris Kobryn, and Steve Cook. Jean B?zivin argued that a good modeling
language should offer support for separation of concerns. Steve Cook from
Microsoft Corp. mentioned that it would be wiser to focus on what a good
modeling tool should look like instead of on the modeling language, because in
the end, a modeling language is of no worth without tool support. It could be
that Steve Cook hinted at what Microsoft was up to in the upcoming months. According
to Steve a good modeling tool should provide:
- a GUI editor
- an XML schema editor
- a Business process modeler
- a CLR class modeler
- a Java class modeler
- a Web services composer
- a Web site designer
- a Data modeler
and should also provide support for:
- Version control
- Configuration management
- Real-time synchronization of models and code
- Definition and application of patterns
Cris Kobryn enumerated some of the qualities a good
modeling language should offer:
- Conciseness
- Precision
- Scalability
- Customizability
- Flexibility
- Intuitiveness
Near the end of the panel, Stuart Kent from Microsoft Corp. triggered a little discussion about
how modeling languages and programming languages are similar or different. In his opinion,
a modeling language is a programming language. Others argued that
modeling languages still lacked proper execution semantics which make them
still different from true programming languages.
In summary, there is still no clear consensus as to what benefits UML 2.0 and MDA
will bring to the community of developers. Another question is whether the
standard is going forward or backward. My gut feeling is that developers should
first stick with the stable version, UML 1.5. Don?t move to UML 2.0 yet! In
theory, the benefits of UML 2.0 are supposed to be obvious, but it seems that
the experts have failed to show the advantages and to focus on the practicality
aspect of UML. For instance, it is not at all straightforward to quickly find
information in the specification. In the future, it will be imperative to
provide developers with outstanding documentation support for UML. Two different
groups of people could be distinguished: those who firmly believe in the advent
of UML 2.0 and MDA (world of theory), and those who remain extremely skeptical
until they see concrete proofs of the benefits of the new standards (real world
developers). 2004 will witness the rebirth of UML and the birth of MDA. Many
people think that UML and MDA will reach their maturity no sooner than year
2006. Let's wait and see what unfolds...
Discuss this article in The Big Moose Saloon!
Return to Top
|
| |
Whizlabs SCBCD Exam Simulator Review
by Andrew Monkhouse, October 2003
Whizlabs have added another excellent product to their stable of exam simulators - aimed squarely at candidates preparing for the Sun Certified Business Component Developer (SCBCD) exam (exam 310-090).
Using this simulator will help the candidate to determine:
- Whether they really know the subject matter (or just think they know it well enough)
- Which areas are they weak in
- Whether they can handle the pressure of the exam
- Whether they will be able to handle the format of the exam (will they understand the way the question is laid out / will they be able to identify the correct answer(s).
The exam simulator will not teach you how to program EJBs, but it will get you used to the types of questions that are used in the exams and highlight the areas you are weak in.
Whizlabs have ensured that all styles of questions that you will see in the real exam are also used in the mock exams, including the new “drag and drop” formats.
All topics which are required for the SCBCD certification are covered in detail, with 350 questions in 5 exam simulations (one "Diagnostic" exam to identify your strengths and weaknesses, 3 "Practice" exams, and one "Final" exam for you to take prior to taking the real exam). There are roughly 25 questions per major topic in Sun's exam.
As well as the 5 exam simulations, a "Quiz" and a "Customised Exam" are also offered to help the candidate concentrate on one particular area of study. So if you are concentrating on the EJB-QL criteria, you can choose to do a quick quiz on questions just relating to that criteria, where questions are popped up onto screen and you have 5 seconds (customisable) to answer the question. Or you could choose to create a customised exam containing as many questions on EJB-QL as are available.
Like the real exam, the exam simulators are timed. If you have still have time remaining when you have answered all questions, you may go back and review your answers.
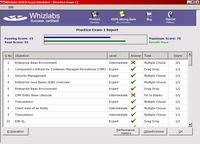
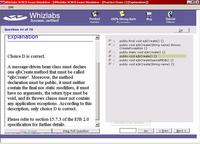
When you have completed a trial exam, quiz, or customised exam, you are shown a report detailing which answers you got right and which were wrong. From here you may view the questions and answers. Each question is shown in it's entirety, along with the answer(s) you chose, and the correct answer(s). Except for the drag and drop questions, each question and answer also had details of why the correct answer(s) are correct and why the incorrect answer(s) are wrong, along with a reference to the section(s) and/or subsection(s) of the EJB specification that covered the question. These explanations along with the references back to the specification are invaluable in learning nuances of the specification and highlighting the gaps in your knowledge. (I was provided with some early releases of Whizlabs' SCBCD offering, so it is possible that a later version may also provide the candidate with references for the drag and drop questions.)
 |
 |
A report is also available showing numbers and percentages of correct answers per exam criteria, making it easy to determine which areas require further study.
You may save your results from each trial exam, quiz, and customised exam, allowing you to come back and view your answers again at a later date, and to see how you have progressed.
You may also take the exams multiple times, and compare your results with previous attempts.
In conjunction with a good book on EJBs (or even just the specifications), this software will be a very resource in your quest to become a Sun Certified Business Components Developer.
Whizlabs are so confident that you will pass the exam after using their simulator that they offer an unconditional money back guarantee in the unlikely event that you fail.
Resources
Whizlabs homepage: http://www.whizlabs.com/
Whizlabs SCBCD exam simulator: Whizlabs SCBCD Simulator FREE Trial Version
|
Discuss this article in The Big Moose Saloon!
Return to Top
|
The Big Moose Saloon Question and Answer of the Month
Mosey on in and pull up a stool. The
JavaRanch Big Moose Saloon is the place to get your Java questions answered.
Our bartenders keep the peace, and folks are pretty friendly anyways, so don't
be shy!
Question: The little white lie, is it worth it?
Answer:The too-long-for-this-column conversation following this topic opener quickly turned to consider the question of honesty during the job hunt. Head on over to the always hot Jobs Discussion Forum, and get yourself an earful of the good advice from Saloon regulars like Mark Herschberg, Alfred Neumann, John Summers, Frank Carver and others in Tony Collins' "Is it worth it?" thread.
Return to Top
|
Movin' them
doggies on the Cattle
Drive
It's where you come to learn Java, and just like the cattle drivers of the
old west, you're expected to pull your weight along the way.
The Cattle Drive forum is where the drivers
get together to complain, uh rather, discuss their assignments and encourage
each other. Thanks to the enthusiastic initiative of Johannes de Jong, you can keep
track of your progress on the drive with the Assignment Log. If you're tough enough
to get through the nitpicking, you'll start collecting moose heads at
the Cattle Drive Hall of Fame.
Fresh rider on the Drive...
Next time you see Dale O'Connor 'round the 'Ranch, give
'em a tip of the hat. Dale's the latest greenhorn to sign up for that
ropin' and codin' adventure known as the Cattle Drive.
Another moose on the wall for...
Yep, that's right, you make it through, you get yerself a nice little moose to hang on the wall. Well, OK, so it's a virtual moose on a virtual wall, but you can be right proud of 'em! Thanks to the efforts of Marilyn deQueiroz, you can now proudly admire your codin' accomplishments at the Cattle Drive Hall of Fame. Check it out, pardner, it's worth a wink.
Them moose sure took a beatin' this month, with the Cattle Drivers
huntin' them down left and right. Wirianto Djunaidi,
Diego Klappenbach, and Sharon Ross all
have moose heads to hang on their walls for completin' the first set of
Cattle Drive codin' assignments. (Turns out Wirianto's had some
experience ropin' cattle already in Colorado territory and even knows
the lay of the land out that way better'n the locals.) Greg
Neef and Marie Mazerolle each bagged their
second moose for completin' the OOP assignments, and both are makin'
progress with servlets.
Nitpicking is hard work
too...
We know they're workin' reeeeeally
hard, after all, we've seen what those assignments look
like once the nitpickers have combed through 'em. Hats
off to Marilyn deQueiroz, Pauline McNamara, and Jason Adam for their dedication
and patience with the pesky vermin that always manage to
make their way into those assignments.
Joinin' the Drive
You think ya got what it takes? You ready for some work and some good learnin'? Then pull up a stool and read up on Joinin' the Drive. Good luck!
Cattle Drive update by Ol' Timer Michael Matola
|
Mosey on over to The Cattle Drive Forum in The Big Moose Saloon!
Return to Top
|
Book Review of the Month
Other books reviewed in
October :
| Java Extreme Programming Cookbook by
Eric M. Burke and Brian M. Coyner | | Jakarta Pitfalls by
Bill Dudney and Jonathan Lehr | | Jess In Action by
Ernest Friedman-Hill | | JSTL: Practical Guide for JSP Programmers by
Sue Spielman | | Software Configuration Management Patterns by
Stephen P. Berczuk, Brad Appleton | | Bug Patterns in Java by
Eric Allen | | Learning UML by
Sinan Si Alhir | | J2EE AntiPatterns by
Bill Dudney, Stephen Asbury, Joseph K. Krozak, Kevin Wittkopf | | Balancing Agility and Discipline: A Guide for the Perplexed by
Barry Boehm, Richard Turner | | Son of Web Pages that Suck by
Vincent Flanders | | J2EE Security for Servlets, EJBs, and Web Services by
Pankaj Kumar | | Embedded Ethernet and Internet Complete by
Jan Axelson | | Java Power Source by
Luis A. Gonzalez, Charles R. Buhrmann | | Text Processing in Python by
David Mertz | | Java 2 Developer Exam Cram 2 (Exam CX-310-252A and CX-310-027) by
Alain Trottier | | Data Access Patterns: Database Interactions in Object-Oriented Applications by
Clifton Nock | | Dungeons and Dreamers: The Rise of Computer Game Culture - From Geek to Chic by
Brad King, John Borland | | Blog On - The Essential Guide to Building Dynamic Weblogs by
Todd Stauffer | | Agile and Iterative Development: A Manager's Guide by
Craig Larman | | Servlets and JSP: The J2EE Web Tier by
Jayson Falkner, Kevin R. Jones | | MDA Explained: The Model Driven Architecture--Practice and Promise by
Anneke Kleppe, Jos Warmer, Wim Bast | | Windows XP Hacks by
Preston Galla | | Professional Struts Applications by
John Carnell, Jeff Linwood, Maciej Zawadzki |
Discuss this book review in The Big Moose Saloon!
Return to Top
|
Scheduled Book Promotions for November and early December:
Take a look at other coming book promotions and learn how to win a free book!
Return to Top
|
Managing Editor: Dirk Schreckmann
Comments or suggestions for JavaRanch's Journal can be sent to the Journal
Staff.
For advertising opportunities contact the Journal
Advertising Staff.
|




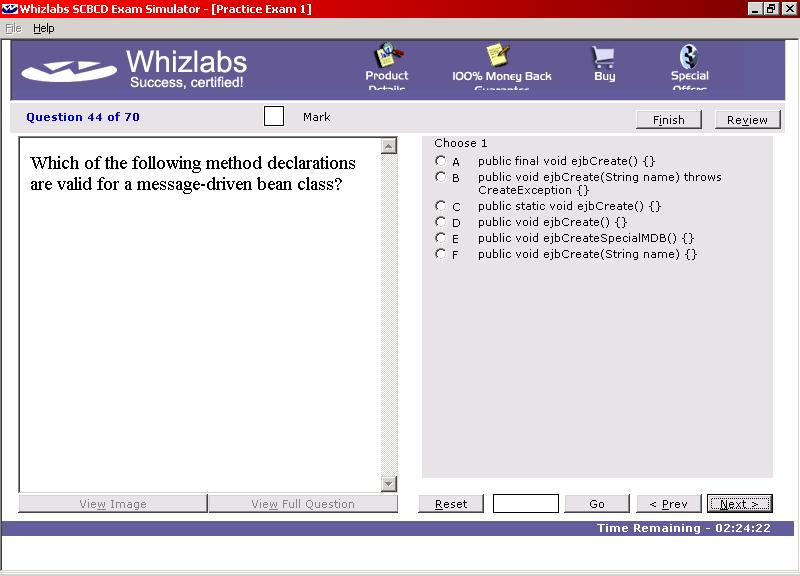
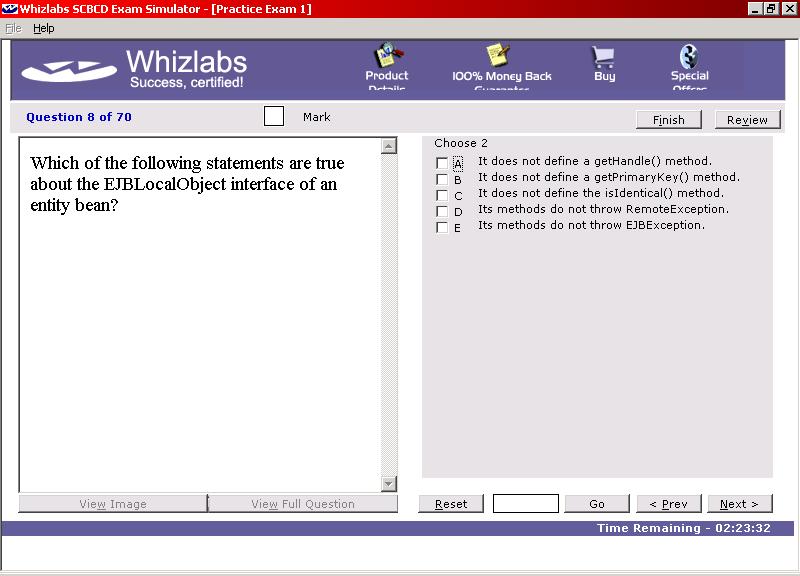
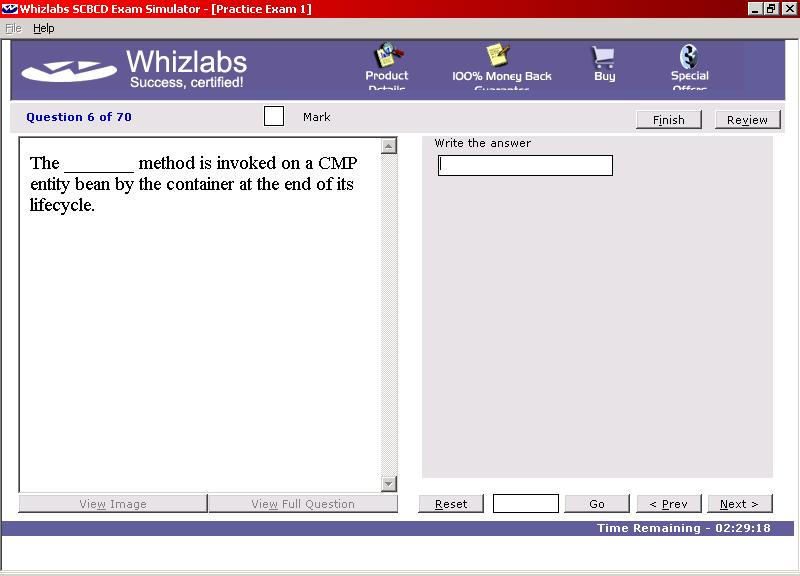
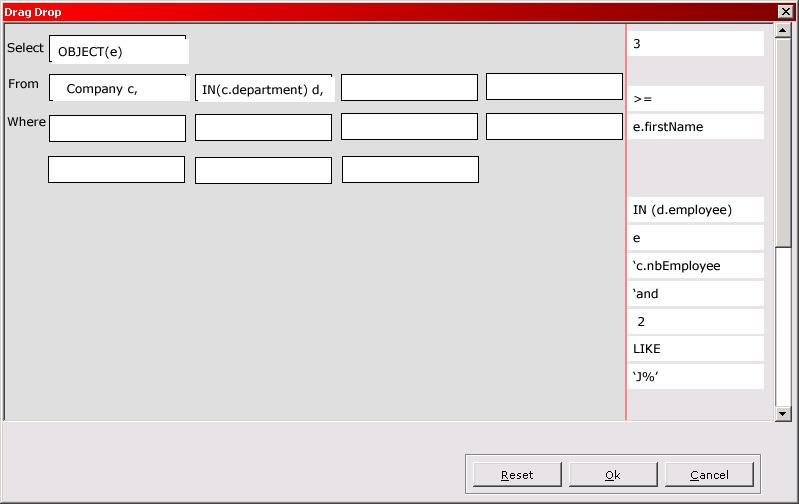
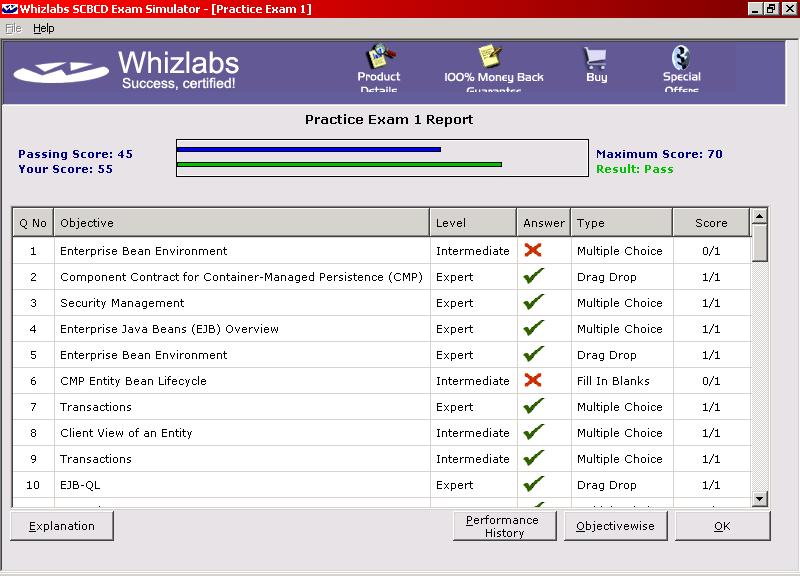
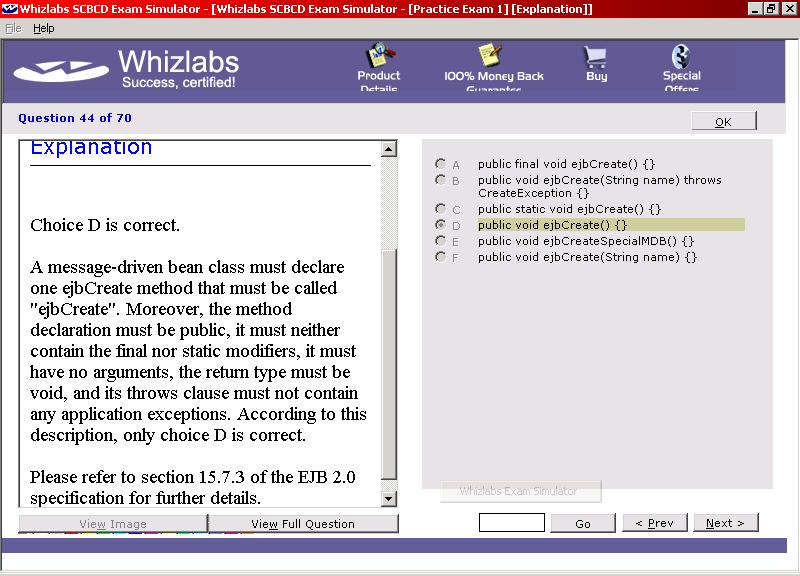

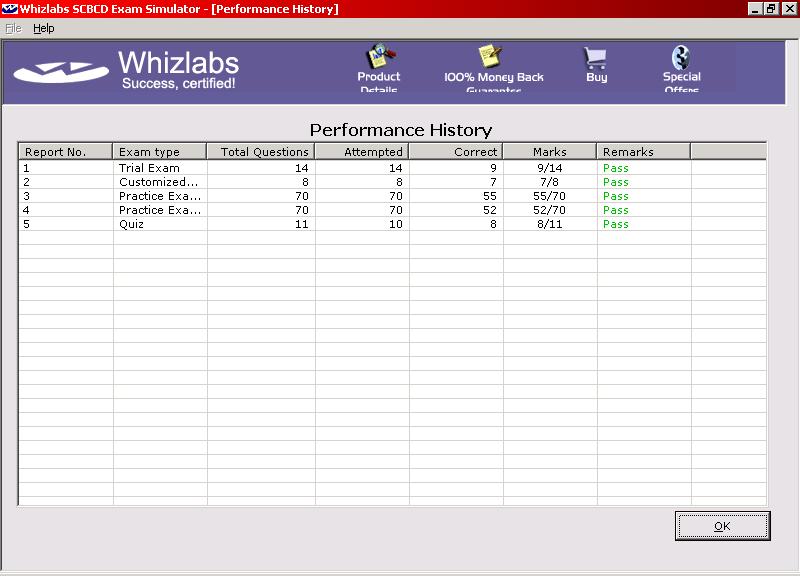

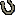
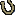
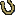
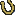

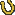

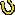
 Contributing to Eclipse: Principles, Patterns, and Plugins
Contributing to Eclipse: Principles, Patterns, and Plugins Core Servlets and JavaServer Pages, Vol. 1: Core Technologies, Second Edition
Core Servlets and JavaServer Pages, Vol. 1: Core Technologies, Second Edition J2EE AntiPatterns
J2EE AntiPatterns Web Services Patterns: Java Edition
Web Services Patterns: Java Edition