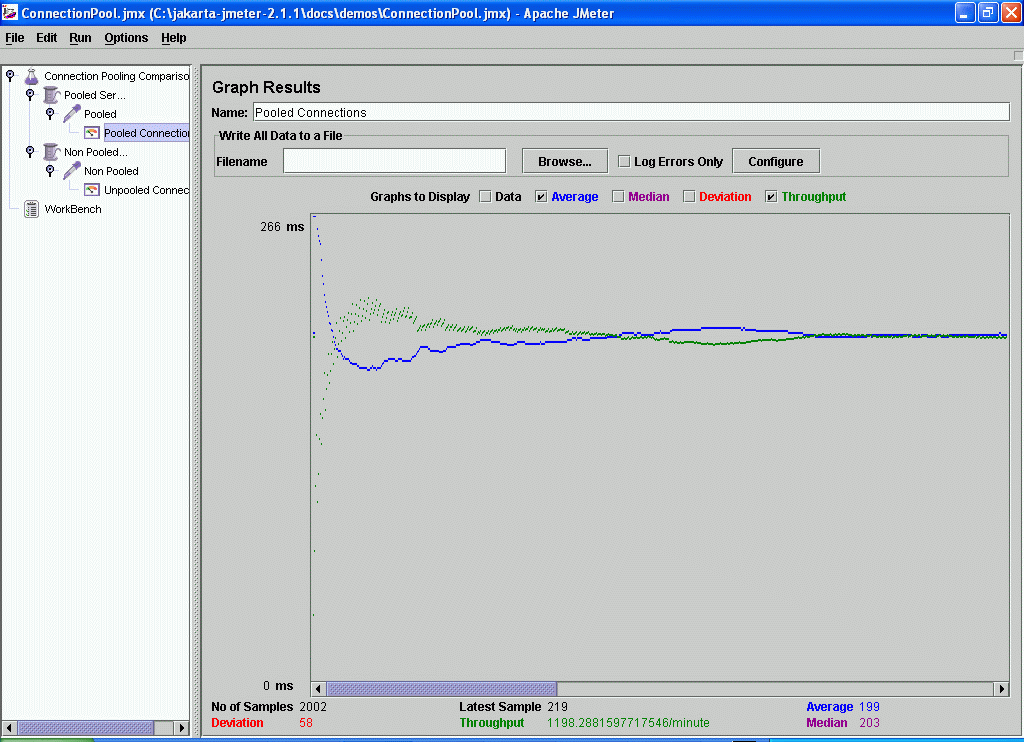
Figure 1. Pooled connections throughput and times. Enlarge
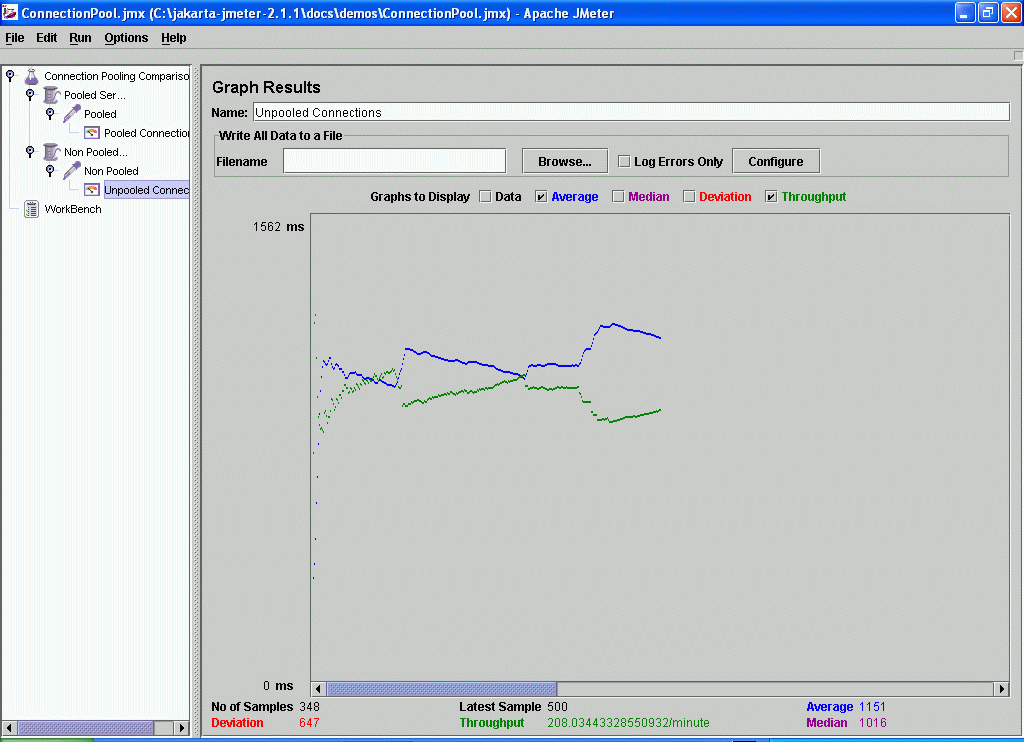
Figure 2. Non pooled connections throughput and times. Enlarge
The addition of JDBC connection pooling to your application usually involves little or no code modification but can often provide significant benefits in terms of application performance, concurrency and scalability. Improvements such as these can become especially important when your application is tasked with servicing many concurrent users within the requirements of sub second response time. By adhering to a small number of relatively simple connection pooling best practices your application can quickly and easily take effective advantage of connection pooling.
There are many scenarios in software architecture where some type of object pooling is employed as a technique to improve application performance. Object pooling is effective for two simple reasons. First, the run time creation of new software objects is often more expensive in terms of performance and memory than the reuse of previously created objects. Second, garbage collection is an expensive process so when we reduce the number of objects to clean up we generally reduce the garbage collection load.
As the saying goes, there is no such thing as a free lunch and this maxim is also true with object pooling. Object pooling does require additional overhead for such tasks as managing the state of the object pool, issuing objects to the application and recycling used objects. Therefore objects that don’t have short lifetimes in your application may not be good choices for object pooling since their low rate of reuse may not warrant the overhead of pooling.
However, objects that do have short lifetimes are often excellent candidates for pooling. In a pooling scenario your application first creates an object pool that can both cache pooled objects and issue objects that are not in use back to the application. For example, pooled objects could be database connections, process threads, server sockets or any other kind of object that may be expensive to create from scratch. As your application first starts asking the pool for objects they will be newly created but when the application has finished with the object it is returned to the pool rather than destroyed. At this point the benefits of object pooling will be realized since, now as the application needs more objects, the pool will be able to issue recycled objects that have previously been returned by the application.
JDBC connection pooling is conceptually similar to any other form of object pooling. Database connections are often expensive to create because of the overhead of establishing a network connection and initializing a database connection session in the back end database. In turn, connection session initialization often requires time consuming processing to perform user authentication, establish transactional contexts and establish other aspects of the session that are required for subsequent database usage.
Additionally, the database's ongoing management of all of its connection sessions can impose a major limiting factor on the scalability of your application. Valuable database resources such as locks, memory, cursors, transaction logs, statement handles and temporary tables all tend to increase based on the number of concurrent connection sessions.
All in all, JDBC database connections are both expensive to initially create and then maintain over time. Therefore, as we shall see, they are an ideal resource to pool.
If your application runs within a J2EE environment and acquires JDBC connections from an appserver defined datasource then your application is probably already using connection pooling. This fact also illustrates an important characteristic of a best practices pooling implementation -- your application is not even aware it's using it! Your J2EE application simply acquires JDBC connections from the datasource, does some work on the connection then closes the connection. Your application's use of connection pooling is transparent. The characteristics of the connection pool can be tweaked and tuned by your appserver's administrator without the application ever needing to know.
If your application is not J2EE based then you may need to investigate using a standalone connection pool manager. Connection pool implementations are available from JDBC driver vendors and a number of other sources.
| import java.sql.*; public class JDBCServlet extends HttpServlet { private Connection connection; public void init(ServletConfig c) throws ServletException { //Open the connection here } public void destroy() { //Close the connection here } public void doGet (HttpServletRequest req, HttpServletResponse res) throws ServletException { //Use the connection here Statement stmt = connection.createStatement(); ..<do JDBC work>.. } } |
Using this approach the servlet creates a JDBC connection when it is loaded and destroys it when it is unloaded. The doGet() method has immediate access to the connection since it has servlet scope. However the database connection is kept open for the entire lifetime of the servlet and that the database will have to retain an open connection for every user that is connected to your application. If your application supports a large number of concurrent users its scalability will be severely limited!
To avoid the long life time of the JDBC connection in the above example we can change the connection to have method scope as follows.
| public class JDBCServlet
extends HttpServlet { private Connection getConnection() throws SQLException { ..<create a JDBC connection>.. } public void doGet (HttpServletRequest req, HttpServletResponse res) throws ServletException { try { Connection connection = getConnection(); ..<do JDBC work>.. connection.close(); } catch (SQLException sqlException) { sqlException.printStackTrace(); } } } |
This approach represents a significant improvement over our first example because now the connection's life time is reduced to the time it takes to execute doGet(). The number of connections to the back end database at any instant is reduced to the number of users who are concurrently executing doGet(). However this example will create and destroy a lot more connections than the first example and this could easily become a performance problem.
In order to retain the advantages of a method scoped connection but reduce the performance hit of creating and destroying a large number of connections we now utilize connection pooling to arrive at our finished example that illustrates the best practices of connecting pool usage.
| import java.sql.*; import javax.sql.*; public class JDBCServlet extends HttpServlet { private DataSource datasource; public void init(ServletConfig config) throws ServletException { try { // Look up the JNDI data source only once at init time Context envCtx = (Context) new InitialContext().lookup("java:comp/env"); datasource = (DataSource) envCtx.lookup("jdbc/MyDataSource"); } catch (NamingException e) { e.printStackTrace(); } } private Connection getConnection() throws SQLException { return datasource.getConnection(); } public void doGet (HttpServletRequest req, HttpServletResponse res) throws ServletException { Connection connection=null; try { connection = getConnection(); ..<do JDBC work>.. } catch (SQLException sqlException) { sqlException.printStackTrace(); } finally { if (connection != null) try {connection.close();} catch (SQLException e) {} } } } } |
This approach uses the connection only for the minimum time the servlet requires it and also avoids creating and destroying a large number of physical database connections. The connection best practices that we have used are:
In general, optimal performance is attained when the pool in its steady state contains just enough connections to service all concurrent connection requests without having to create new physical database connections. If the pooling implementation supports purging idle connections it can optimize its size over time to accommodate varying application loads over the course of a day. For example, scaling up the number of connections cached in the pool during business hours then dynamically reducing the pool size after business hours.
In order to compare the difference between using non pooled connections and connection pooling I built a simple servlet that displays orders in Oracle's sample OE (Order Entry) database schema. The testing configuration consists of Jakarta's JMetric load testing tool, the Tomcat 5.5 servlet container and an Oracle 10g database instance. Tomcat and Oracle were running on separate 512MB machines connected by 100Mbps Ethernet.
The servlet is written to use either pooled or non pooled database connections depending on the query string passed in its URL. So the servlet can be dynamically instructed by the load tester to use (or not use) connection pooling in order to compare throughput in both modes. The servlet creates pooled connections using a Tomcat DBCP connection pool and non pooled connections directly from Oracle's thin JDBC driver. Having acquired a connection, the servlet executes a simple join between the order header and line tables then formats and outputs the results as HTML.
A JMeter test plan was created to continuously run the servlet in pooled and non pooled connection modes within thread groups of 4 threads each. A JMeter results graph is attached to each thread group to measure throughput.
As this example shows connection pooling can make a significant difference to your application's performance. In this example the throughput of 1198 requests per minute using pooled connections is almost six times faster than using non pooled connections. (In practice, the gains in your own application may not be this dramatic since our example does very little JDBC work per connection.)
If your project uses many short lived JDBC connections and does not use connection pooling now then I recommend that you seriously consider using pooling to improve your application's performance and scalability. Additionally, if your application adheres to the simple best practices presented in this article you will maximize the benefits of using connection pooling and make it truly transparent to your application.
David Murphy is Program Manager of JDBC Products at JNetDirect.
www.jnetdirect.com