by Bear Bibeault
The code I wrote nine months ago sucks. And I'm happy about it.
Of course back then I thought what I was writing was the bee's knees, and that the code that I had written nine months before that was what sucked. And at that time, I thought that it was the code written nine months prior to that was what sucked. And on and on and on back to the beginning of my programming career, when 110 baud teletypes were all the rage.
So why am I so happy about it? Simple: if I can look back at code I had written previously and know that the code I am writing today shows significant improvement, it means that I am still learning and growing as a coder.
The day that I look at my older code and think that it is perfect will be a sad day indeed, as it will mean either: (a) I have learned all that there is to learn (highly unlikely), or (b) that my brain has calcified and can accept no more information. Either of these would be a sad state of affairs.
So as long as I keep finding that my current level of coding is better than my previous level, I know that I am continuing to improve my skills. And that makes me happy.
So what's the point of that little story?
As with our own personal development skills, the aggregate of skills and knowledge in the development community also progresses and improves with time. This most visibly manifests itself with the establishment of design patterns, which Wikipedia defines as: "a general repeatable solution to a commonly-occurring problem in software design".
The "commonly-occurring problem" I wish to discuss in this article is how best to structure a web application for use with Scriptless JSP Pages; a problem whose solution we will find, like my own journey in the field of software development, has grown and improved over time.
Where the Heck Are We?
I first started writing JSP pages back in the late 1990's prior to even the first official release of the JSP 1.0 Specification. To give you an idea of how primitive this beta of JSP (0.9.2, if I recall correctly) was, what we now know as the <jsp:useBean> action was defined as just <BEAN> — the standard JSP actions did not at that time use XML syntax, and so the JSP actions looked just like any other HTML markup.
Needless to say, not many people were yet writing web applications using JSP pages at that time, and so no common patterns had yet to emerge from the gestalt of the development community.
So we winged it.
And in hind-sight, not all that well.
With the freedom to place Java code directly on the pages, we did.
All of it.
A lot of it.
In droves.
And boy, were we sorry.
Not only was the code hard to read, embedded as it was amidst tons of Javascript and HTML markup, it was untestable, unable to be reused, difficult to refactor, and just a plain bear (in a bad way) to deal with.
It didn't take us long to discover — as soon as we tried to modify, extend, maintain, or fix bugs in this application — that this "model" of just jumbling all the code — client-side markup as well as server-side Java — into the JSP page itself had some severe limitations.
I dubbed this anti-pattern (if you could call it a pattern at all — even a bad one) either the Model 0 pattern of JSP Development, or the model-less pattern.
Both monikers make a lot of sense: Model 0 is a good measure of the worth of this "pattern" (zero), and model-less can be abbreviated to the highly appropriate "mess".
The following figure diagrams the simple interaction that takes place when a request is submitted to such a page. It is indeed a simple structure to create and envision, but the drawbacks vastly out-weigh any such benefit.
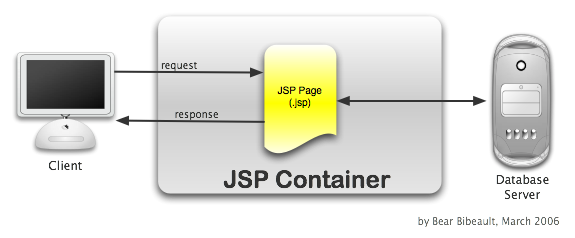
Use the Bean, Luke!
There had to be a better way!
Not alone in that thinking, patterns for getting things under better control soon emerged.
With the emergence of a finalized JSP Specification, basic bean-manipulation standard actions were defined that still exist to this day. Across the JSP development community, people figured out that factoring the processing code out of the pages and into Java classes was a good way of eliminating some of the problems introduced by having on-page code.
Moving code off-page and into classes afforded better testability and reuse, and reduced the complexity of the pages themselves. All of this helped make the code base more flexible, extensible and maintainable.
Once means of doing so is to factor code off the pages and into Java classes that adhere to the JavaBean standards. These classes could then be used and controlled from the JSP page using the JSP standard actions, as well as by simplified scriptlet code.
This pattern, known as "Model 1", retains the JSP as the unit of control, but delegates processing to the Java beans. The following figure diagrams how a request interacts with the various components in this pattern.
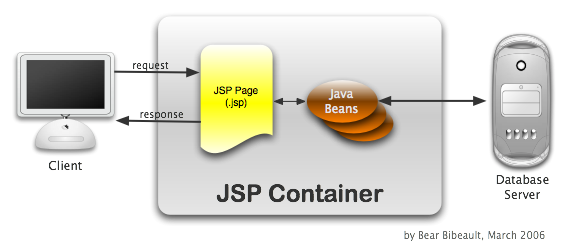
I've Got a Bad Feeling About This
Factoring out processing code into beans proved to be a great improvement to the structure of web applications using JSP, but there were still some problems and limitations.
The primary purpose of a JSP is to serve as a template for rendering the presentation format (usually HTML) as the results of a request. By retaining the JSP as the unit of control (the unit to which submissions are directly made), the assumption is made that the view to be rendered is known prior to the submission. And this is not always true.
In many cases, decisions need to be made, using the submitted data and other available information, before the most appropriate page to display can be determined. This means that sometimes the page that is the target of the submission is not the page that needs to be rendered.
Such decisions need to made at an early stage in the request processing as anyone who has received the dreaded "response has already been committed" IllegalStateException can attest.
This can lead to some design ugliness as pages would need to redirect or forward to each other, creating a rather messy network out of the control flow for the application.
One can also end up writing pages that aren't pages at all -- they just do some processing before shifting off to another page. And that's just wrong. Why use a mechanism designed as a templating mechanism for rendering output if there's no output to be generated at all?
Better patterns needed to emerge.
Control, Control, You Must Learn Control
It is apparent that submitting directly to a JSP page in order to make decisions about which JSP page to show is less than optimum. Something other than an output generation template should make such a decision prior to a JSP page being invoked.
This line of thinking led to the concept of the Page Controller.
Martin Fowler describes the Page Controller as:
An object that handles a request for a specific page or action on a Web site.
He also states that a page can act as its own controller (which puts us squarely back into Model 1 territory), but more often the Page Controller is a servlet that is invoked as a result of the POST or GET action. This servlet performs any setup or processing necessary to prepare the page for viewing prior to forwarding the request to the JSP page template for view rendering. When such processing involves business logic or database interaction, frequently such processing is delegated to other classes.
This pattern, in which a controller servlet is the target of submission rather than the JSP pages themselves, has been dubbed the "Model 2" pattern and is generally considered a good approximation of the Model-View-Controller Pattern, more affectionately known as MVC, as applied to web applications.
The following figure diagrams how a request interacts with the various components in this pattern.
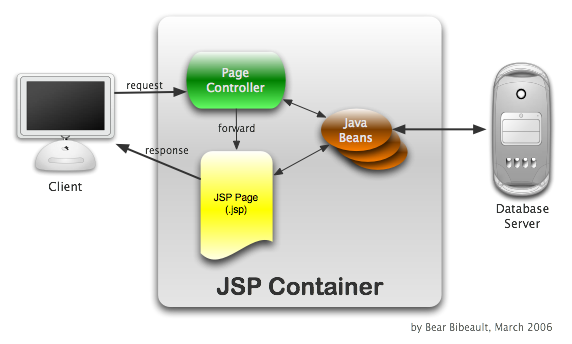
This pattern offers numerous advantages. Not only does it remove the previously mentioned messiness involved with JSPs being used for control rather than rendering, but by adhering to the principles of Separation of Concerns it "inherits" all the advantages attributed to that principle.
Houston, We Have a Problem
A common problem that arises when employing the Model 2 pattern occurs when users start hitting that dang Refresh button on the browser. It sometimes seems that there are few forces in the Universe more powerful than the urge to hit Refresh when looking at a page of data.
Why would that cause a problem? Let's examine a typical scenario:
- The user is on an e-commerce site, looking at their "shopping cart" page which exposes various operations; one of which allows the user to delete items from the cart.
- The user clicks on the delete button for an item.
- A request to "delete item" is posted to the server passing a unique value identifying the item to be removed as a parameter.
- The servlet controller for "delete item" receives the request along with the item id. It delegates to the business logic code to remove the item from the cart and receives the new list of items (presumably with the deleted item removed). The controller places the list of cart items on the request and forwards to the JSP page that displays the cart.
- The cart page is refreshed, showing the user the updated cart contents.
- All is well and good until the user decides to go up to the browser's control bar and click that dang Refresh button. This, of course, causes the last request to be re-submitted. So the "delete item" controller gets called as before, but this time with the id of an item that is not in the cart. Disaster and disgrace ensue.
It's also easy to imagine the problems that ensue when similar scenarios take place for inserting items, adjusting quantities, or other non-idempotent actions.
In mathematics, the term idempotent means "relating to or being a mathematical quantity which when applied to itself under a given binary operation (as multiplication) equals itself". In computer science, it is take to mean an operation that causes no change in state. Therefore, a non-idempotent operation is one that causes the state (usually referring to the Model) to change; deleting an item from the cart, for example.
The knee-jerk reaction of "How do I disable the Refresh button in the browser" is obviously not the appropriate solution to this problem.
The problem actually lies in not recognizing that there are two distinct type of controllers in action here:
-
Controllers that performs a non-idempotent operation (in
other words, changes the business state) and are therefore not safe to repeat.
I call such controllers Task Controllers, and such controllers should rarely forward to a JSP page on their own. Rather they should delegate such responsibility to the following:
-
Controllers that prepare a page for display by fetching the data required and performing other preparatory operations. Since they are not changing business state, these idempotent controllers are safe to repeat.
These controllers I term Page Controllers as they precisely fit the description for the Page Controller pattern described beforehand. These controllers never perform non-idempotent operations, and their sole purpose is to prepare the request for the JSP page, usually by fetching whatever data is necessary for display on the JSP.
Look at step 4 in the above scenario. The same controller that deletes the item also prepares the page for redisplay. This is a frequent error in controller design. Not only does it give rise to the problem described above, it's a non-modular design that forces every cart controller to embed code to prepare the cart page for display.
Rather, a Page Controller should handle preparing the request for display of the cart JSP separately from the Task Controllers that perform cart actions (such as deleting an item from the cart).
Making this change, our new Step 4 would be:
-
The task controller for "delete item" receives the request along
with the item id. It delegates to the business logic code to remove the
item from the cart.
It then redirects to the page controller for the "show cart" page, which fetches the list of updated cart items, places the items on the request, and forwards to the cart JSP page.
By breaking the server-side activity into two pieces: one that performs the non-idempotent operation, and one that prepares the page for display, our refresh problem has been solved. The user can bang away on the refresh button to his heart's desire until the cows come home with no ill effects other than repeatedly hitting the server.
Note that the key to making this scenario work as expected is not only that we broke the two pieces of the operation into logically separate units, we used a redirect to chain them together.
This sequence of events, which was described in this older article, is a good one to follow for these types of operations.
This technique has sometimes been referred to as the Post-Redirect-Get (or PRG) Pattern. But, if you've already read Paul Wheaton's article on the misuse of the term "Pattern", one could argue that this technique is not yet widely known enough to deserve the moniker of "Pattern". So we'll call it the PRG Technique.
Web application operations generally fall into two categories:
- Those that display data.
- Those that perform an operation (non-idempotent or otherwise) and display the results.
The first of these type of operation follow the simple steps of:
- A GET request is made identifying the data to be displayed to a Page Controller.
- The Page Controller gathers the data from the business tier and places it on the request as scoped variables.
- The Page Controller forwards to the JSP page which display the data.
The second of these type of operation follows the slightly less simple steps of:
- A POST request is made to a Task Controller with data need to complete the controller's task.
- The Task Controller instructs the business tier to perform the appropriate operation(s).
- The Task Controller redirects to the appropriate Page Controller to display the results of the operation, which then follows the steps outlined in the previous scenario.
The following figure diagrams how such a request interacts with the various components in this pattern.
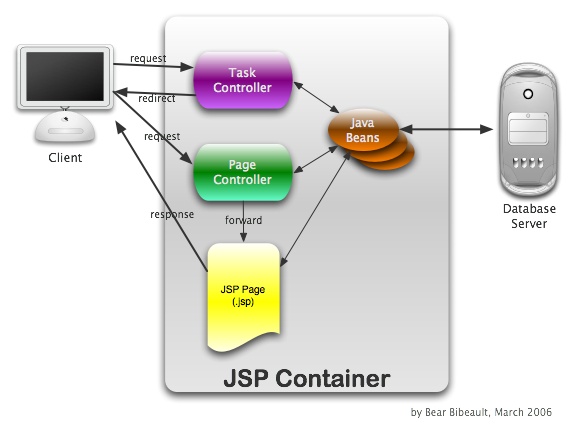
I Hope It Won't Be Too Crowded
The Page Controller pattern has a lot going for it, but an issue that could be seen as a major drawback is the footprint it requires in the deployment descriptor (web.xml).
Think about it for a moment. In the pattern described above, each Task Controller (one fronting each possible non-idempotent task) and each Page Controller (one fronting each page) is a separate servlet. As such, each must be declared in the deployment descriptor (unless you are doing something silly like using the appropriately much-maligned Invoker) by using a <servlet> element. Moreover, each also requires a <servlet-mapping> to specify the URL pattern to invoke the servlet.
So for each controller in the web application, something along the lines of the following is required:
<servlet>
<servlet-name>DeleteItemTaskController</servlet-name>
<servlet-class>
org.bibeault.some.project.controllers.DeleteItemTaskController
</servlet-class>
</servlet>
...
<servlet-mapping>
<servlet-name>DeleteItemTaskController</servlet-name>
<url-pattern>/task/deleteItem</url-pattern>
</servlet-mapping>
And that's a minimum — if init parameters and other declarations are added, the footprint for each controller can be even more wordy.
It's easy to see that for even a modest-sized web application, the controller declaration footprint in the deployment descriptor can become quite large and unwieldy.
Is there something that can be done about that?
The Front Man Cometh
Enter the Front Controller pattern.
The Front Controller pattern uses a single servlet to field all requests for controllers, eliminating the need for each and every controller to be declared separately in the deployment descriptor. The front controller servlet only requires one <servlet> element and one <servlet-mapping> element to be declared to field requests for all the controllers.
"Now wait just a minute!" you might be saying. "Isn't that exactly what the Invoker is? The Invoker that you just pointed out was evil?".
Astute! Yes, the Invoker is an instance of a Front Controller. Just not a very good one for the various reasons pointed out in the linked article; one major issue being that it reveals the class path of servlets in the URL. Not the most smashing of ideas.
But it's not always the case that one bad apple spoils the whole pattern.
It's actually a simple matter to eliminate the need to reveal the class path of the controller servlets by abstracting what appears in the URL.
The "unit of control" in a Front Controller environment is generally not a servlet at all, but rather a delegate class that implements an interface that the Front Controller uses to manipulate the controller unit. Because these delegate classes represent operations to be performed, they themselves are instances of a pattern known as the Command Pattern and are therefore usually termed Commands.
Information on the URL used to invoke the Front Controller servlet is used to uniquely identify which Command class should be used to service the request.
For example, the Front Controller employed by the Struts package typically uses a servlet mapping of *.do where whatever appears as the prefix of the ".do" is used to lookup the actual class path of the Command (called "actions" in Struts) in an internal configuration map.
Another example, the pattern that I usually use, is to employ a servlet mapping such as /command/* where the prefix "command" triggers the front controller, and the rest of the path info is used to lookup the Command class in an internal map. It would be typical to see URLs along the lines of:
http://some.server.com/webapp/command/deleteItem http://some.server.com/webapp/command/insertItem http://some.server.com/webapp/command/doSomethingWonderful
Note that in both of these examples, the mapping of the abstracted controller id ("deleteItem", for example) to an actual Command class is handled by an internal configuration map. Which means, of course, that there must be configuration to set up that map on behalf of the Front Controller in the first place.
The perspicacious reader may at this point be thinking "Well, that just moves the configuration of the controllers from the deployment descriptor to some other file!". And that reader would be correct.
But... typically, the configuration notation for associating the controller id keys with the class path to their Commands is much simpler than the servlet and servlet mapping elements in the deployment descriptor (though Struts isn't necessarily a stellar example of this), and segregating the association declarations from the web.xml declarations keeps the latter from getting swamped by the former.
This allows the Front Controller to create instances of the Command classes (without the need to reveal any class path information in URLs) and to manipulate them via a Front Controller-defined interface, which typically contains an "execute" (or "perform") method that the Front Controller calls to transfer control to the Command class instance.
The following figure diagrams how a request interacts with the various components in this pattern.
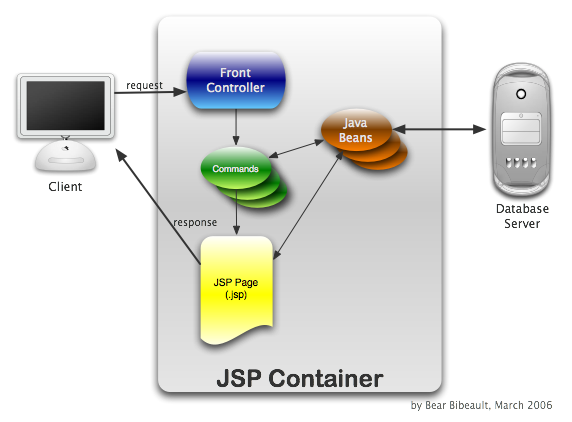
This diagram shows a simple idempotent request. The PRG Technique described previously also applies in the Front Controller scenario in which Commands can be Task Commands (typically non-idempotent, operational) or Page Commands (always idempotent, page preparatory).
What's That Got To Do, Got to Do With It?
You may be wondering at this point what an article on web application structure patterns is doing in a series on Scriptless JSP pages. Except for mentioning JSP pages as the end target of a request, JSP wasn't even much of a topic throughout this article!
The answer is that the success of using Scriptless JSP Pages, by their very nature, depends greatly on the structure of the web application in which they are employed.
In previous articles in this series it has been stressed how Scriptless JSP Pages should be completely devoid of processing and be pure view components. Previous articles have also stressed how the data structures sent to such pages should adhere to patterns that are EL-friendly so as to keep the pages themselves simple and straight-forward.
Such considerations require that a suitable web application structure be employed in order to enable Scriptless JSP Pages to shine!
It's easy to see that the Model 2 Pattern, which factors processing out of the JSP pages into controllers written as Java classes, is extremely well-suited to web applications that employ scriptless pages.
Whether you employ a Front Controller or not in the Model 2 pattern is fairly immaterial as far the the pages themselves go, but it is a pattern that I highly favor in my own web applications.
Pop Quiz!
The sub-section titles in the article are all famous quotes, or take-offs of famous quotes, from movies, TV or music. Can you identify them all?
This article has been slightly modified from its original published form to update some terminology choices based upon discussion in the forum topic for this article. Special thanks to Bruno Boehr and Ernest Friedman-Hill for their help in nailing this down.