What is pagination ?
The first time I heard the word pagination, I thought "What's that?". Then I googled and found out that it's a fancy word for splitting search results into bite size pages that the user can snack into. Pagination depends on some factors. It might even depend on what type of framework you use to deliver your solution. An off the shelf API that paginates on a web browser might not work with a Swing application that wants to paginate results. Let's look at some of the ways to paginate.
Using an off the shelf solution to paginate results
This method has its own pros and cons like the rest. To begin with it's quite easy to find an API that's out there, and to use its functions to paginate your results. Often all you have to do is to provide the API, details about the number of results, how many pages to display etc. The API may even be configurable by the user if it is flexible enough. For example JavaWorld featured an article quite a while back about using such an API. Given below is the code related to the pagination tag (a custom tag)
<pagination-tag:pager start="<%=start%>" range="<%=range%>" results="<%=results%>"/>
Given the start position, range and total number of results we can let the API do its job and paginate the results. This kind of solution requires the least work from the developer. The code is ready made and available. All the developer needs to do is to know how to use the API and things work by themselves. (DisplayTag is another such tag libray; see the reference section below for a link.) Although such APIs may reduce development time they may not be as flexible as we might want them to be. If a client requires changes to the way pagination occurs in the application we may have to dive down to the guts of the API and find a solution if it is not available. Worse still, if you don't have the source code to the library you may be in trouble. The pagination tag is a custom tag that a developer can use to paginate his/her results. Imagine if you need to change the code contents of the custom tag because the client wants a change to the way we paginate. Any open solution must be used with caution. Anything that is free and saves time is welcome as long as it does not complicate the solution at a later stage in its life.
Writing your own pagination logic
There are 2 ways (mostly) through which you can fetch your data. One would be to fetch all the results (hence the term greedy) and display it to a user after caching the results. The other approach is to get a selection of the results each time a user requests the data from the search query.
Fetching results the greedy way
I am a big fan of patterns. A particular pattern called the ValueListHandler is very useful when dealing with paginating greedily. This pattern is reusable across several queries and can help your pagination process. A class diagram of the ValueListHandler pattern is illustrated below.
Class diagram: ValueListHandler
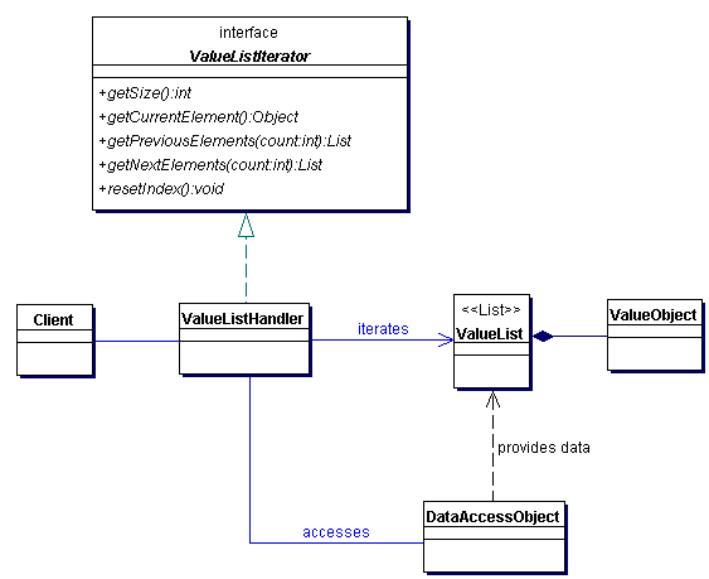
The idea is that a client uses a ValueListHandler, which accesses a DAO to return a ValueList. Each value list can contain a couple of value objects (The DAO and VO patterns are mentioned in the references section if you need to go through them). Every time the user needs results to be displayed it can be handled gracefully by asking the ValueListHandler a sub list from the ValueList. Since the ValueList caches the results there is not need to go the database again to fetch the next set of results when the user clicks "Next". Here is a sequence diagram to explain it better.
Sequence diagram: ValueListHandler
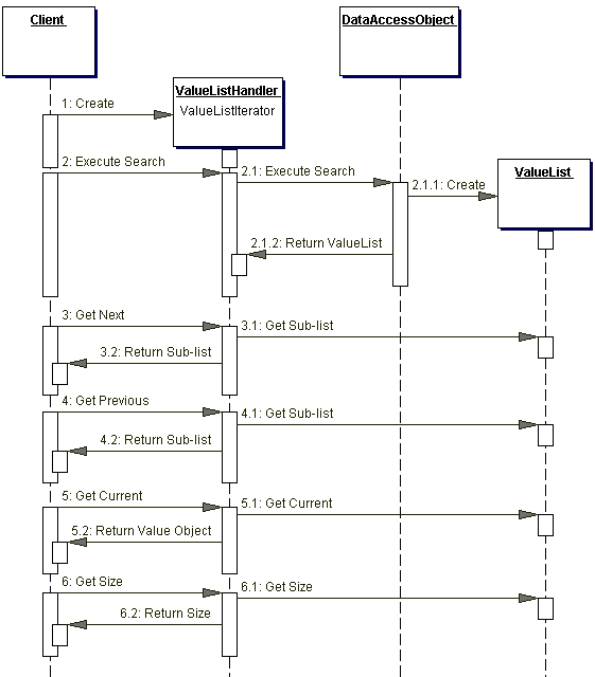
Every time the user needs the next (or previous) result set you can ask the ValueListHandler for the next/previous sub list. If you allow the value list to store a list of Objects you can use this solution to set any type of VO into the ValueList and apply this pattern across several searches. You will of course have to cache the ValueListHandler in memory. You will also have to down cast the list of objects from the ValueList to your VO type everytime you want to display the data in the object.
Fetching results the not so greedy way
There is a little problem with the solution that was described above. What if your search result returns 100,000 matches? Your user may have to wait for a long time and be a very unhappy camper indeed. So it often makes sense to fetch only the number of records the user wants to see. Different database have different methods to limit the query size. Oracle uses ROWNUM, and Sybase uses LIMIT. The queries below give you an example of how you can restrict your result set.
Sybase: (Give me rows 0 to 10 of the result)
SELECT * FROM TABLE WHERE {CONDITION} LIMIT 0, 10
Oracle: (Give me the rows between min_row_to_fetch and max_row_to_fetch )
SELECT *
FROM ( SELECT /*+ FIRST_ROWS(n) */ a.*, ROWNUM rnum
FROM ( your_query_goes_here, with order by ) a
WHERE ROWNUM <= :MAX_ROW_TO_FETCH )
WHERE rnum >= :MIN_ROW_TO_FETCH;
Oracle's version of the query limitation is a little different because of the way it treats ROWNUM. In order to make the SQL more database agnostic, you can paginate by requesting data by using a sub set of the primary keys that you are interested in. For example if your data list contains the primary keys {1,34,25,56,333,23,99,101} you can create a sub list {1,34,25,56} and fetch this list. The next sub list would be {333,23,99,101}. Pagination is then possible with the following SQL:
SELECT * FROM TABLE WHERE PRIMARY_KEY IN (MY_SUB_LIST)
Another drawback with the greedy approach is that the data becomes stale once you cache it. If your application changes the data in the result set frequently you may have to consider the accuracy of your results when you choose a solution.
Which technique should I use?
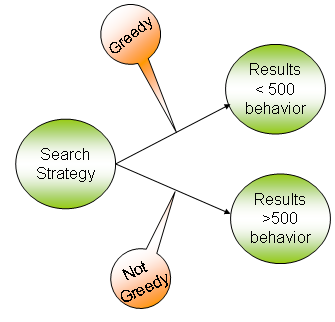
Whichever solution fits your requirements. The solution may not even be one of the 3 listed here. These are 3 common approaches to paginating and usually fit the bill based on the user's response time requirements. My personal favorite is to add a Strategy pattern on top of this. If the number of results is less than 500 (say) I use the greedy technique to display the results. If it is more than 500 I use the non-greedy technique to display the results since the user may have to wait for a long time. Be sure to consider the drawbacks carefully in each case. At the risk of dumbing down the Strategy pattern, an illustration for this scenario is given below. Practically one would switch between various implementations of an interface to achieve this. Check the reference section below for more information on this. I would recommend the Head First Design Pattern book or the Gang Of Four design pattern book.
Strategy based on result set size
Conclusion
Each scenario would solve the problem given a certain boundary. You should choose wisely based on what solution best suits you. In the end it does not matter how we solve the problem as long as the client's requirements are met and the design of the solution is flexible to accommodate future changes.