HTML -> XML conversion with XSLT and visual tools
Step 1. Converting input HTML pages into XHTML with Tidy
Step 2. HTML structure visualization with Merlot.
Step 3.Writing XPath expression with The Xpath Visualizer
Step 4. Applying XSLT and testing the result
| Fighting chaos, case 1: XPath concat() function Fighting chaos, case 2: <xsl:choose> element Fighting chaos, case 3: descendant-or-self (//) axis |
Our bunkhouse stretches itself on a large territory of 16 HTML files with total length about 500Kb. Page layout is done using tables and it makes corresponding HTML structure rather regular. However, the files were maintained by different people at different time and as a result, some peculiarities are observed at lower structure levels. For example, inside <td> tags the target information is normally placed in a sequence of <a><font> tags, but sometimes the sequence is reversed and we get <font><a>sequence. XSLT provides enough flexibility to write expressions and instructions matching both "regular" and "irregular" structures, but investigating such cases by reading nude HTML code would be tedious and boring. Free visual tools supplied by XML community turn this job into an exiting data hunting.
Input HTML:
<TD rowspan="2">
<a target="amazon" href="http://www.amazon.com/exec/obidos/ASIN/0201616467/electricporkchop">
<IMG height=140 src="images/practical.jpg" width=112 ></A>
</TD>
Problems:
1. tag a first coded in lower case and closing tag </A> in upper case
2. tag IMG doesn't have matching closing tag
3. Values of height and width attribute are not enclosed in quotes
Tidy output:
<td rowspan="2">
<a target="amazon" href="http://www.amazon.com/exec/obidos/ASIN/0201616467/electricporkchop">
<img height="140" src="images/practical.jpg" width="112" /></a>
</td>
All problems are magically fixed.
| Take a look at source of any bunkhouse page and you will think that it's easier to get lost in HTML jungles than
to say anything meaningful about its structure. We can took advantage of the fact that XML editors can visualize
the document structure as a tree. For this proposal Merlot,
open source Java based XML editor, was used. (Remark: colorful markup on the picture is not a part
of Merlot service and was added for better visualization) By looking at the tree, created by Merlot, it's easy to see that our information is placed in table 3, and to write XPath expression to match it: <xsl:template match="html/body/table[3]"> The same information is repeated for each row in the table, so we iterate through rows using <xsl:for-each> instruction. Inside the template we have: <xsl:for-each select="./tr"> Further investigations shows that each book is described in a group of three rows. Information about a book's title and author, for example, is located in the first row. To check if the current row is the first in a triple, we can use XPath position() function: <xsl:if test="position() mod 3 = 1"> |
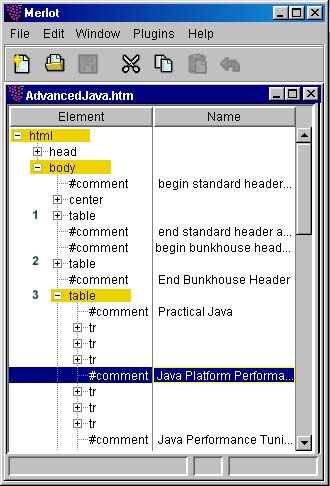 |
| Let's define where our "title-to-be" element is located. I expanded <tr> tag to investigate its
inner structure. A book's title is located inside tags: <tr>,
<td>, <a>, <font>
respectively and author in tags <tr>, <td>.
We can check this by looking at HTML code: <!-- Practical Java --> <tr align="left"> <td colspan="3" height="20"> <a target="amazon" href="http://www.amazon.com/ exec/obidos/ASIN/0201616467/ electricporkchop"> <font size="5">Practical Java</font> <br /></a> by Peter Haggar</td> </tr> Our XPatch expression for titles looks like: ./td/a/font/text() (Here "." refers to the current element which is <tr> ) And for authors we have: ./td[1]/text() |
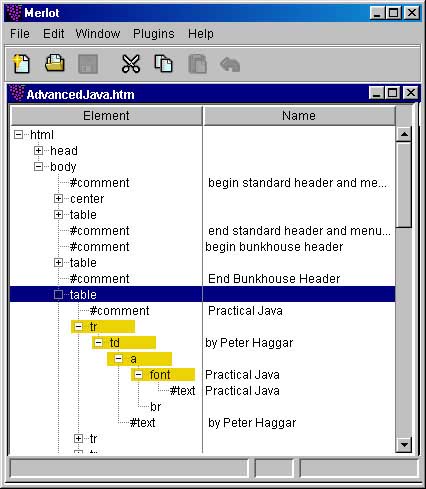 |
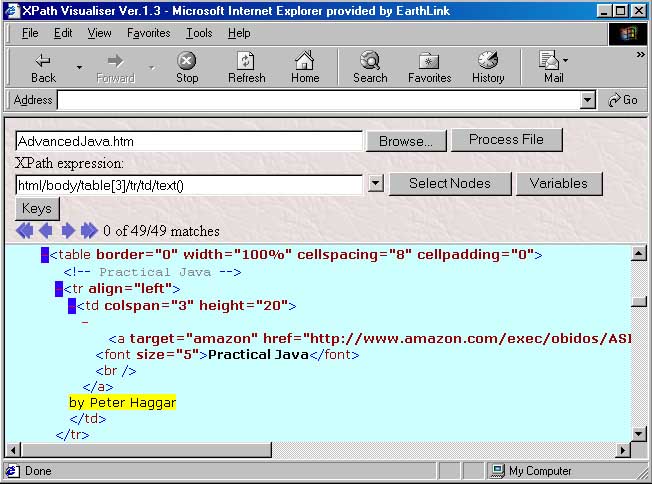
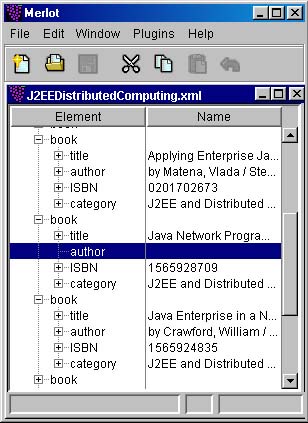
Fighting chaos, case 2: <xsl:choose> element
Book titles provide us with another problem: target information was ocasionlly located in the content of <font> tag, which was eòclosed in <a> tag (variant 1), on another occasion it was the content of <a> tag, enclosed in <font> (variant 2). <xsl:choose> element came to the rescue and incorporated such diversity,
Variant 1:
<td colspan="3" height="20"> <a target="amazon" href="http://www.amazon.com/exec/obidos/ASIN/0131103628/electricporkchop"> <font size="5">The C Programming Language</font><br /> </a> by Mark Williams Company</td>
matching XPath expression is: ./td[1]/a/font/text()
Variant 2:
<td colspan="3" height="20"> <font size="5"> <a target="amazon" href="http://www.amazon.com/exec/obidos/ASIN/0201325829/electricporkchop"> Programming and Deploying Java Mobile Agents with Aglets</a></font><br /> by Danny B. Lange, Mitsuru Oshima</td>
matching XPath expression is: ./td[1]/font/a/text()
Solution: <xsl:choose>
Here we simply test which variant we encounter and choose appropriate XSLT instruction.
<xsl:choose>
<xsl:when test="./td[1]/a/font">
<title>
<xsl:value-of select="normalize-space(./td[1]/a/font/text())"/>
</title>
</xsl:when>
<xsl:when test="./td[1]/font/a">
<title>
<xsl:value-of select="normalize-space(./td[1]/font/a/text())"/>
</title>
</xsl:when>
</xsl:choose>
Fighting chaos, case 3: descendant-or-self (//) axis
Yet another problem was provided by ISBN-to-be element. Target information was located as "href"
attribute of <a> tag, but <a>
tag itself could happen either as a direct descendant of <td>
tag (variant 1), or as a child of <font> (variant
2) - the same problem that complicated our book titles
mining.
Variant 1
<td colspan="3" height="20"> <a target="amazon" href="http://www.amazon.com/exec/obidos/ASIN/0131103628/electricporkchop"> <font size="5">The C Programming Language</font><br /> </a> by Mark Williams Company</td>
Matching XPath expression would be ./td[1]/a/@href
Variant 2
<td colspan="3" height="20"> <font size="5"> <a target="amazon" href="http://www.amazon.com/exec/obidos/ASIN/0201633469/electricporkchop"> TCP/IP Illustrated, Volume 1</a> </font><br /> by W. Richard Stevens</td>
Here we have <font> tag between <td> and <a>. We could write ./td[1]/font/a/@href but there is a better solution: ./td[1]//a/@href By putting // between <td> and <a> we are saying "select all <a> tags which are descendant of <td> tag, regardless of how many depth levels they are located". This XPath expression matches both variants above.